26. Vision Language Pretraining#
26.1. CLIP#
26.1.1. Overview#
CLIP, which stands for “Contrastive Language-Image Pre-training,” is a multimodal model that uses contrastive learning. CLIP is trained on text-image pairs with the goal of teaching the model to learn matching relationships between text and images via contrastive learning [Fig. 26.1]. The model consists of two parts: a text encoder and an image encoder, which are used to extract text and image features and produce semantic vectors.

Fig. 26.1 Using contrastive learning, CLIP jointly trains an image encoder and a text encoder to predict the correct pairings of a batch of (image, text) training examples. Image from [RKH+21].#
The trained text encode and image encodder can be directly used in zero-shot application setting, as shown in Fig. 26.2.
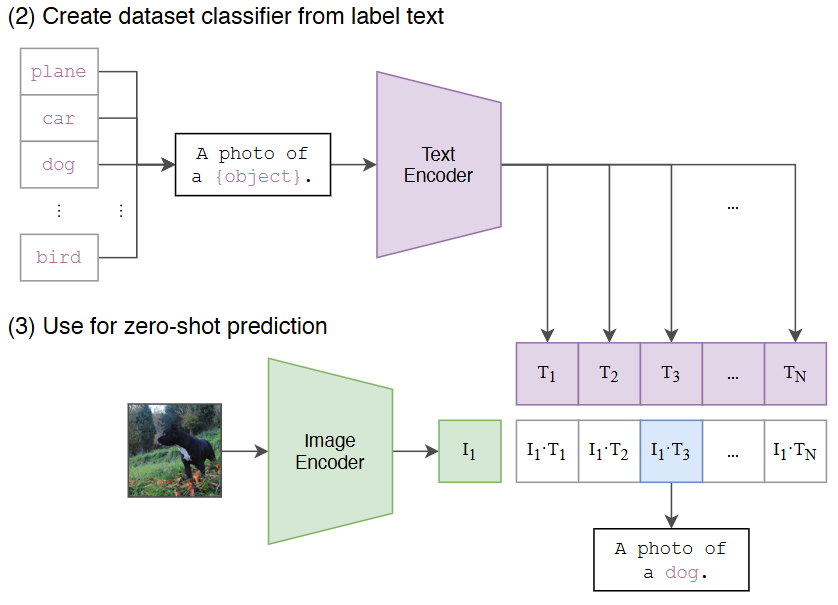
Fig. 26.2 At test time the learned text encoder synthesizes a zero-shot linear classifier by embedding the names or descriptions of the target dataset’s classes. Image from [RKH+21].#
The key conclusion is that CLIP model learns from natural language supervision and is capable of performing various tasks during pre-training, such as OCR, geo-localization, and action recognition, while demonstrating competitive performance in zero-shot transfer tasks.
26.1.2. Detailed Implementations#
In the original study, two architectures were considered for the image encoder:
ResNet (such as ResNet-50, ResNet-101, etc., with modifications like ResNetD improvements, pooling, attention pooling)
Vision Transformer (ViT); the text encoder uses a Transformer architecture.
A major motivation for natural language supervision is the large quantities of data of this form available publicly on the internet. At the then time of this research, the high-quality image-text parallel data available is on the scale ~10 million. CLIP employed the following data collection strategy: They created a new dataset called WIT (WebImageText), containing 400M image-text pairs. The data was collected by searching for text-image pairs containing 500,000 queries (the query list was based on frequent words from English Wikipedia, high-traffic article names, two-word phrases, and WordNet synonym sets), ensuring the data covers a wide range of visual concepts. Each query included up to 20,000 image-text pairs, with the final dataset having a total word count comparable to the WebText dataset used to train GPT-2.
Given a mini-batch of \(N\) image-text pairs whose embeddings are \(\{e_{I,1}, e_{I,2},..., e_{I,N}\}\) and \(\{e_{T,1}, e_{T,2},..., e_{T,N}\}\). The contrastive loss is given by
where \(\tau\) is the temperature coefficient.
# image_encoder - ResNet or Vision Transformer
# text_encoder - CBOW or Text Transformer
# I[n, h, w, c] - minibatch of aligned images
# T[n, l] - minibatch of aligned texts
# W_i[d_i, d_e] - learned proj of image to embed
# W_t[d_t, d_e] - learned proj of text to embed
# t - learned temperature parameter
# extract feature representations of each modality
I_f = image_encoder(I) #[n, d_i]
T_f = text_encoder(T) #[n, d_t]
# joint multimodal embedding [n, d_e]
I_e = l2_normalize(np.dot(I_f, W_i), axis=1)
T_e = l2_normalize(np.dot(T_f, W_t), axis=1)
# scaled pairwise cosine similarities [n, n]
logits = np.dot(I_e, T_e.T) * np.exp(t)
# symmetric loss function
labels = np.arange(n)
loss_i = cross_entropy_loss(logits, labels, axis=0)
loss_t = cross_entropy_loss(logits, labels, axis=1)
loss = (loss_i + loss_t)/2
26.2. BLIP#
26.2.1. Introduction#
BLIP (Bootstrapping Language-Image Pretraining) is a multimodal framework proposed by Salesforce in 2022. It unifies understanding and generation by introducing cross-modal encoders and decoders, enabling cross-modal information flow, and achieving SOTA results in multiple vision and language tasks. In AIGC, it’s commonly used to generate prompts for images. Good prompts are crucial for fine-tuning cross-attention, for example, the Automatic Prompt in ControlNet is generated by BLIP.
The term Bootstrapping refers to the fact that the training data comes from web image-text pairs, which contain a lot of noise. Therefore, an online data labeling and cleaning task was added, where the processed data is used to iterate on the original model.
26.2.2. Model Architecture#
BLIP introduces MED (Multimodal mixture of Encoder-Decoder), a multimodal hybrid architecture that enables effective multi-task pre-training and transfer learning. MED includes
Two unimodal encoders (Image Encoder and Text Encoder);
One image-grounded text encoder, which uses additional cross-attention layers to model vision-language interactions,
One image-grounded text decoder, which uses causal self-attention layers on text interactions and a shared cross-attention layers to model vision-language interactions.
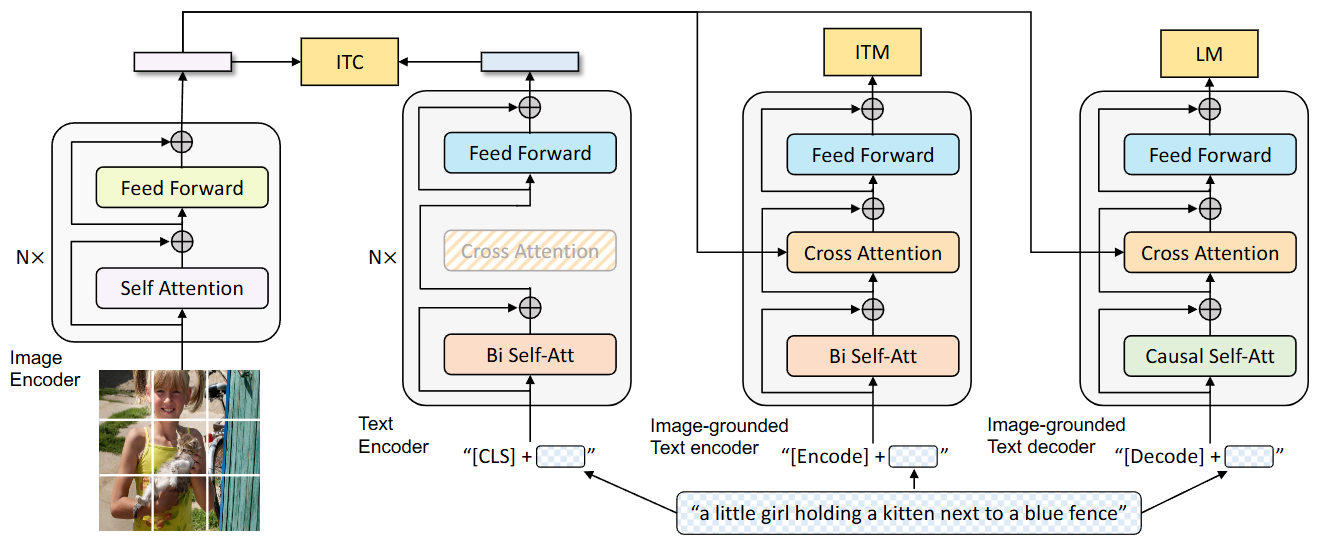
Fig. 26.3 Pre-training model architecture and objectives of BLIP (same parameters have the same color). Image from [LLXH22].#
There are three different loss functions to align different modules:
An image-text contrastive (ITC) loss to align the image and text encoders.
An image-text matching (ITM) loss to guide the image-grounded encoder to distinguish between positive and negative image-text pairs.
A language modeling (LM) loss to guide the generation of text captions given images via autoregression.
26.2.3. Training Strategy#
To effectively utilize the large amount of image-text pairs obtained from the web, which often contain inaccurate or even incorrect information, BLIP proposes the CapFilt (Captioning and Filtering) module for caption generation and filtering. It first learns from noisy image-text pairs, then generates and filters to create new datasets, which are used to iteratively optimize the original model.
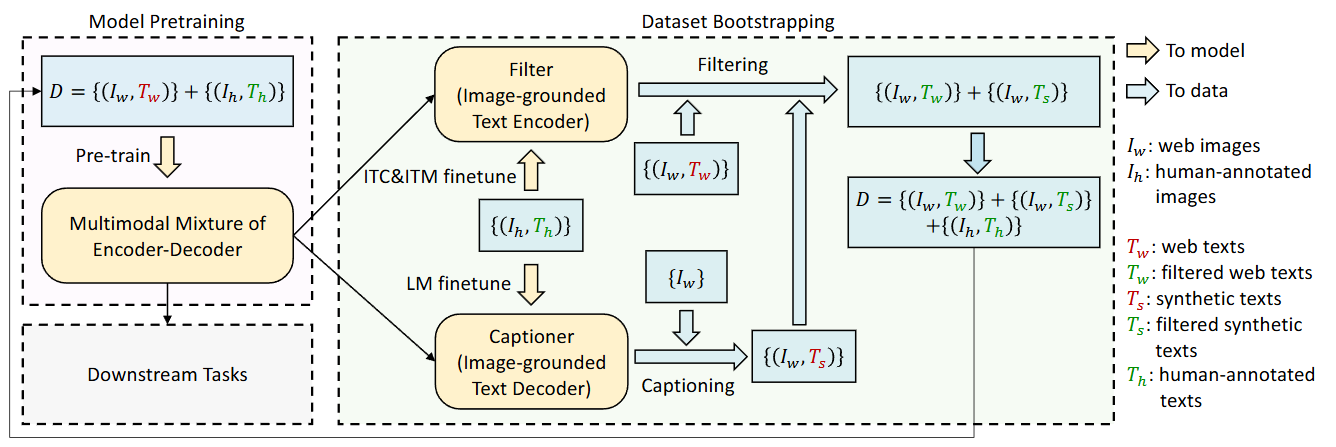
Fig. 26.4 Learning framework of BLIP. A captioner is used to produce synthetic captions for web images, and a filter is used to remove noisy image-text pairs. The resulted bootstrapped dataset is used to pre-train a new model. Image from [LLXH22].#
CapFilt consists of two modules:
captioner, which generates captions for web images,
Filter, which filters out noisy captions from both original web text and synthetic text.
Experimental results show that by generating more training data from captioner and filter, the BLIP model achieves consistent performance improvements across various downstream tasks, including image-text retrieval, image captioning, visual question answering, visual reasoning, and visual dialogue.
Both Captioner and Filter are initialized from pre-trained models and separately fine-tuned on manually annotated datasets.
Captioner is an image-grounded text decoder, which is fine-tuned on manually annotated datasets with an LM objective, decoding text for given images. Here, given web images, the Captioner generates synthetic captions.
Filter is an image-grounded text encoder that is fine-tuned with ITC and ITM objectives to learn whether text matches images, removing noisy text from both original web text and synthetic text.
26.2.4. Downstream Application#
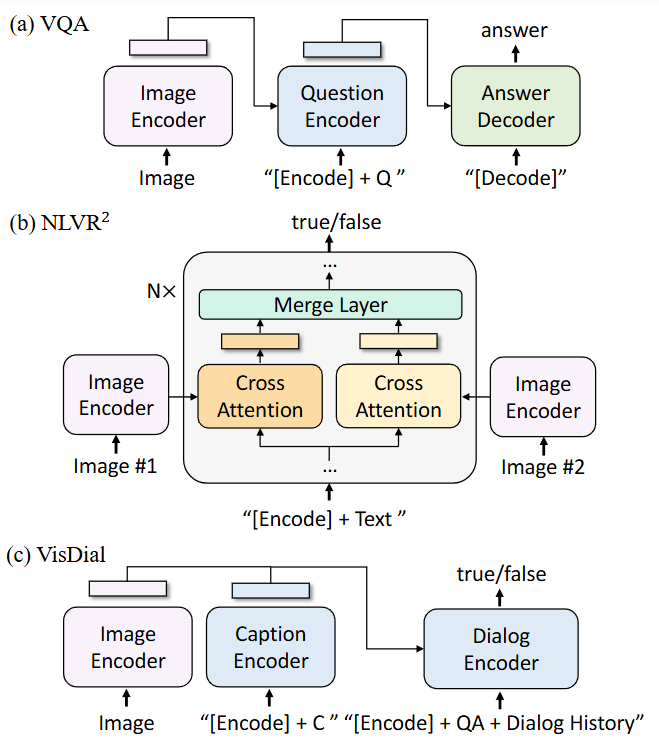
Fig. 26.5 Model architecture for the downstream tasks. Q: question; C: caption; QA: question-answer pair. Image from [LLXH22].#
Visual Question Answering (VQA) requires the model to predict an answer given an image and a question. During downstream finetuning, we can first encode the image-question input into multimodal embeddings using an image encoder and a text encoder with cross-attention to image embedding. The resulted multimodal embeddings are then given to an text to produce answer. The VQA model is finetuned with the LM loss using ground-truth answers as targets.
Natural Language Visual Reasoning (NLVR2) asks the model to predict whether a sentence describes a pair of images. First, each image is encoded into embeddings using unimodal image encoder. These image embeddings are then sent to the image-grounded text encoder, in which there exist two cross-attention layers to process the two input images, and their outputs are merged and fed to the FFN. The merge layer performs simple average pooling in the first 6 layers of the encoder, and performs concatenation followed by a linear projection in layer 6-12. An MLP classifier is applied on the output embedding of the [Encode] token.
Visual Dialog (VisDial) extends VQA in a natural conversational setting, where the model needs to predict an answer not only based on the image-question pair, but also considering the dialog history and the image’s caption. Fig. 26.5 adopts the discriminative setting where the model ranks a pool of answer candidates. Image and caption text are encoded separately using unimodal encoders, then image and text embeddings are concatenated and passed to the dialog encoder through cross-attention. The dialog encoder is trained with the ITM loss to discriminate whether the answer is true or false for a question, given the entire dialog history and the image-caption embeddings.
26.3. BLIP-2#
26.3.1. Model Architecture#
BLIP-2 [LLSH23] from Saleforces, which aimed to improve multimodal performance and reduces training costs by leveraging pre-trained vision models and language models. The pre-trained vision models provide high-quality visual representations, while the pre-trained language models offer powerful language generation capabilities.
BLIP-2 consists of a pre-trained Image Encoder, a pre-trained Large Language Model, and a learnable Q-Former.
Image Encoder: Responsible for extracting visual features from input images. The paper experimented with two network architectures: ViT-L/14 trained with CLIP and ViT-g/14 trained with EVA-CLIP.
Large Language Model: Responsible for text generation. The paper experimented with both decoder-based LLM and encoder-decoder-based LLM.
Q-Former: Responsible for bridging the gap between visual and language modalities. It consists of two sub-modules: Image Transformer and Text Transformer, which share the same self-attention layers.
Image Transformer extracts visual features by interacting with the image encoder. Its input consists of learnable Queries, which interact with each other through self-attention layers and with frozen image features through cross-attention layers. It can also interact with text through shared self-attention layers.
Text Transformer serves as both text encoder and decoder. Its self-attention layers are shared with the Image Transformer. Depending on the pre-training task, different self-attention masks are applied to control how Queries and text interact.
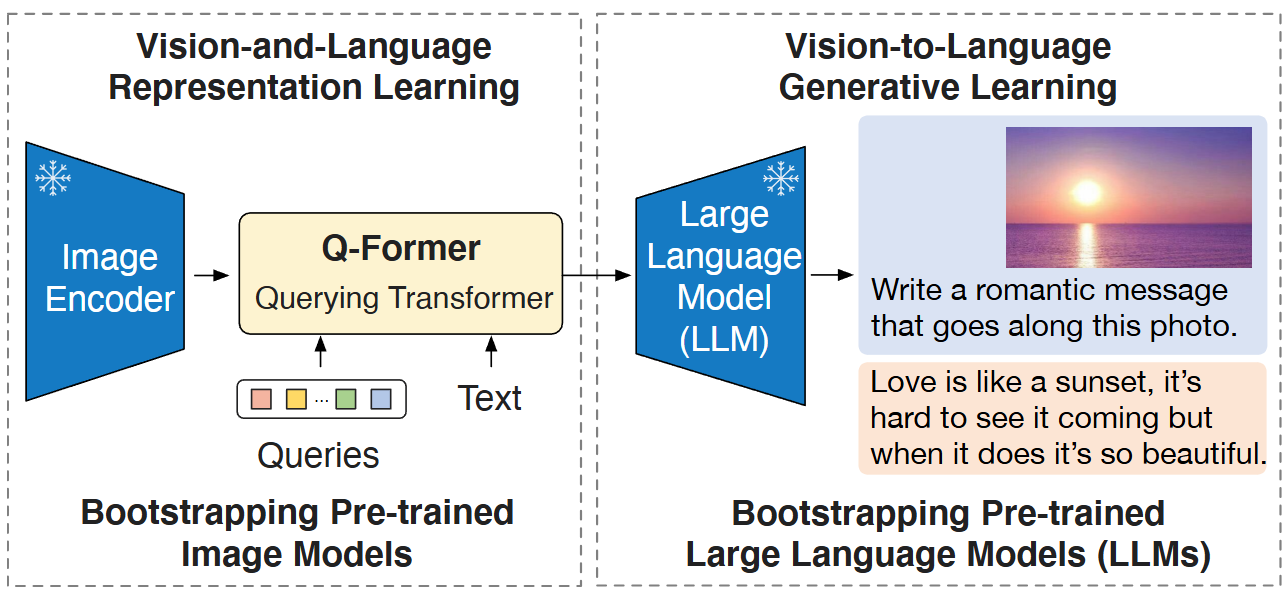
Fig. 26.6 Overview of BLIP-2 framework. A lightweight Querying Transformer is trained via a two-stage strategy to bridge the modality gap. The first stage bootstraps vision-language representation learning from a frozen image encoder. The second stage bootstraps vision-to-language generative learning from a frozen LLM, which enables zero-shot instructed image-totext generation. Image from [LLSH23].#
Remark 26.1 (Design considerations for fusing image understanding signals)
One way to fuse image understanding signal into text LLM is first going through a semantic conversion stage - using caption models to generate textual descriptions of images/videos (scenes, events, entities, etc.), then feeding these textual descriptions (or perform some preprocessing, like summarization beforehand) into the LLM.
This approach involves indirectly converting visual semantics into textual semantics through a visual Captioner (semantic conversion stage), then better adapting the textual semantics through Prompt+LLM (semantic adaptation stage), and finally using this as input for the target LLM to create an MLLM (semantic fusion stage).
While this approach is straightforward and easy to implement, its limitations are obvious - there is information loss at the semantic conversion stage, in which the final LLM model cannot perceive fine-grained information from the original visual input, which severely limits the MLLM’s potential.
One design idea is Q-Former is to use a learnable query vector plus cross-attention mechanism to directly fuse image signals features in the semantic vector space. The usage of learnable query vector also resembles the idea of learnable soft prompt [LARC21] in LLM fine-tuning.
26.3.2. Training Strategy#
To reduce computational costs and avoid catastrophic forgetting, BLIP-2 freezes both pre-trained image and language models during pre-training. However, simply freezing pre-trained model parameters makes it difficult to align visual and text features. To address this, BLIP-2 proposes a two-stage Q-Former pre-training approach to bridge the modality gap:
Representation learning stage
Generative learning stage.
Representation Learning Stage: In the representation learning stage, Q-Former is connected to the frozen Image Encoder, using image-text pairs as the training set. Through jointly optimizing three pre-training objectives, different attention mask strategies are applied between Query and Text to control the interaction between Image Transformer and Text Transformer. Fig.4 Model architecture of Q-Former and Vision-Language Representation Learning
ITC (Image-Text Contrastive Learning): ITC’s optimization objective is to align image embeddings with text embeddings, aligning Query embeddings from Image Transformer output with text embeddings from Text Transformer output. To prevent information leakage, ITC uses unimodal self-attention masks, not allowing Query and Text to attend to each other. Specifically, Text Transformer’s text embedding is the output embedding of the [CLS] token, while Query embeddings contain multiple output embeddings. Therefore, it first computes the similarity between each Query output embedding and the text embedding, then selects the highest one as the image-text similarity.
ITG (Image-grounded Text Generation): ITG trains Q-Former to generate text conditioned on the input image, forcing Query to extract visual features containing textual information. Since Q-Former’s architecture doesn’t allow direct interaction between the frozen image encoder and text tokens, the information needed for generating text must first be extracted by Query and then passed to text tokens through self-attention layers. ITG uses multimodal Causal Attention masks to control Query and Text interaction - Queries can attend to each other but not to Text tokens, while each Text token can process all Queries and its preceding Text tokens. Here, the [CLS] token is replaced with a new [DEC] token as the first text token to indicate the decoding task.
ITM (Image-Text Matching): ITM is a binary classification task that learns fine-grained alignment between image and text representations by predicting whether an image-text pair is a positive or negative match. Each Query embedding from Image Transformer output is input into a binary linear classifier to obtain corresponding logits, which are then averaged to calculate the matching score. ITM uses bidirectional self-attention masks, allowing all Queries and Text to attend to each other.
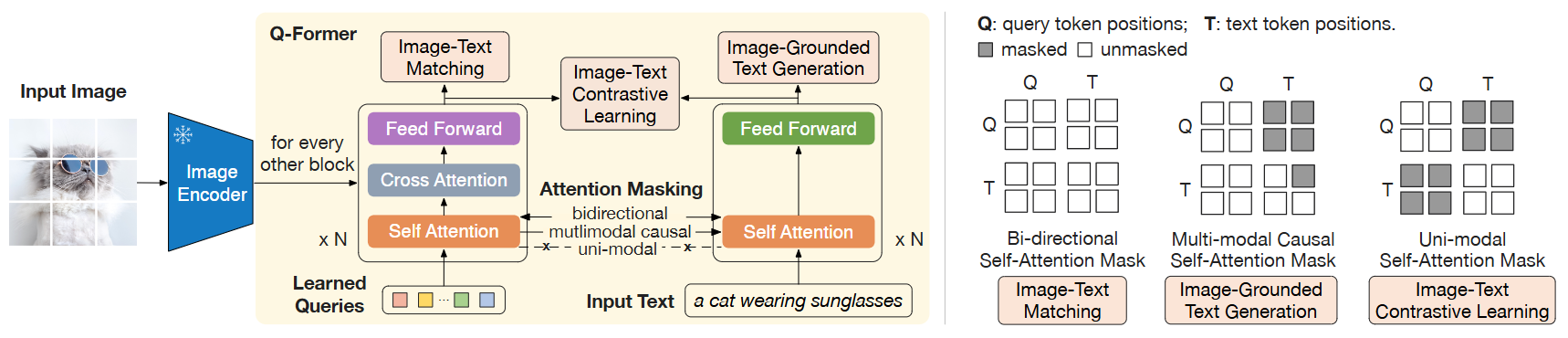
Fig. 26.7 (Left) Model architecture of Q-Former and BLIP-2’s first-stage vision-language representation learning objectives. We jointly optimize three objectives which enforce the queries (a set of learnable embeddings) to extract visual representation most relevant to the text. (Right) The self-attention masking strategy for each objective to control query-text interaction. Image from [LLSH23].#
Generative Learning: In the generative pre-training stage, Q-Former is connected to the frozen LLM to leverage the LLM’s language generation capabilities. Here, a fully connected layer linearly projects the output Query embeddings to the same dimension as the LLM’s text embeddings, then adds these projected Query embeddings before the input text embeddings. Since Q-Former has been pre-trained to extract visual representations containing language information, it can effectively serve as an information bottleneck, providing the most useful information to the LLM while removing irrelevant visual information, reducing the burden on the LLM to learn vision-language alignment.
BLIP-2 experimented with two types of LLMs: decoder-based LLMs and encoder-decoder-based LLMs. For decoder-based LLMs, language modeling loss is used for pre-training, where the frozen LLM’s task is to generate text based on Q-Former’s visual representations. For encoder-decoder-based LLMs, prefix language modeling loss is used for pre-training, where the text is split into two parts: the prefix text is concatenated with visual representations as input to the LLM encoder, while the suffix text serves as the generation target for the LLM decoder.
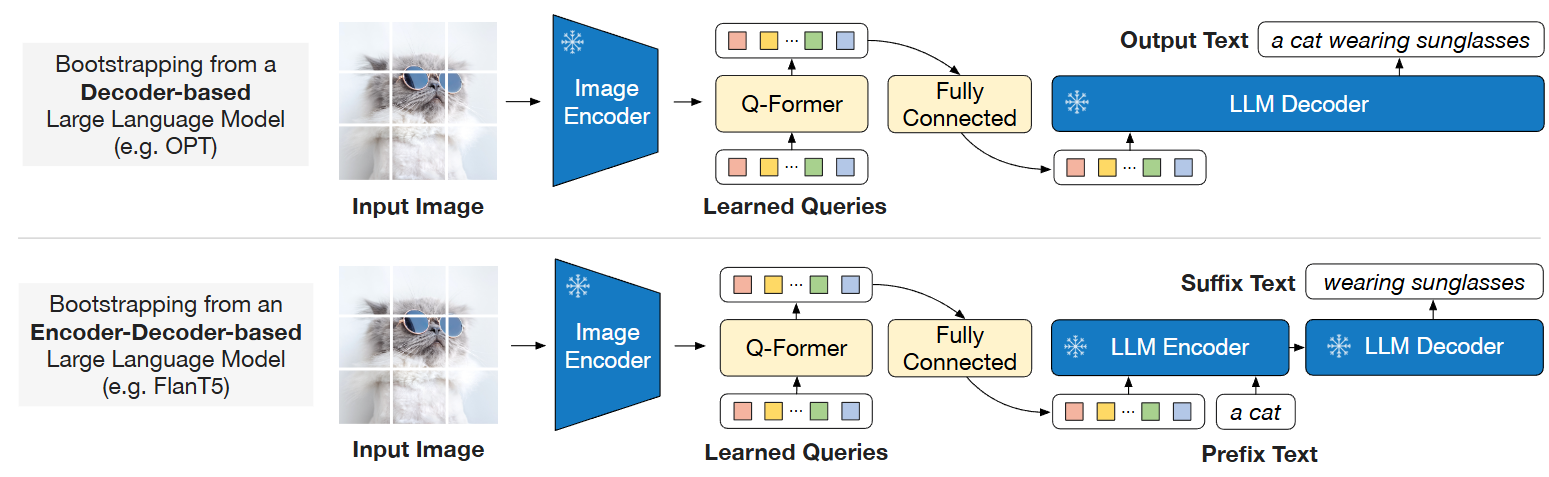
Fig. 26.8 BLIP-2 second-stage vision-to-language generative pre-training, which bootstraps from frozen large language models (LLMs). (Top) Bootstrapping a decoder-based LLM (e.g. OPT). (Bottom) Bootstrapping an encoder-decoder-based LLM (e.g. FlanT5). The fully-connected layer adapts from the output dimension of the Q-Former to the input dimension of the chosen LLM. Image from [LLSH23].#
26.4. Instruct BLIP#
Large-scale pre-training and instruction tuning [LZY24] have been successful at creating general-purpose language models. InstructBLIP [LLWL24], a vision-language instruction tuning framework that enables general-purpose models to solve a wide range of visuallanguage tasks through a unified natural language interface.
InstructBLIP adopts a model architecture similar to BLIP-2, which consists of a visual encoder, Q-Former, and LLM. The visual encoder extracts features from the input image and feeds them into the Q-Former. Q-Former’s input includes both learnable Queries and Instruction. The internal structure of Q-Former is shown in [], where the learnable Queries interact with the Instruction through Self-Attention, and interact with the input image features through Cross-Attention, encouraging the extraction of task-relevant image features.
Q-Former’s output is fed into the LLM through an FC layer. The pre-training process of Q-Former follows BLIP-2’s two steps:
Without using LLM, pre-train Q-Former’s parameters while keeping visual encoder parameters fixed, with vision-language modeling as the training objective.
Train Q-Former’s parameters while keeping LLM parameters fixed, with text generation as the training objective.
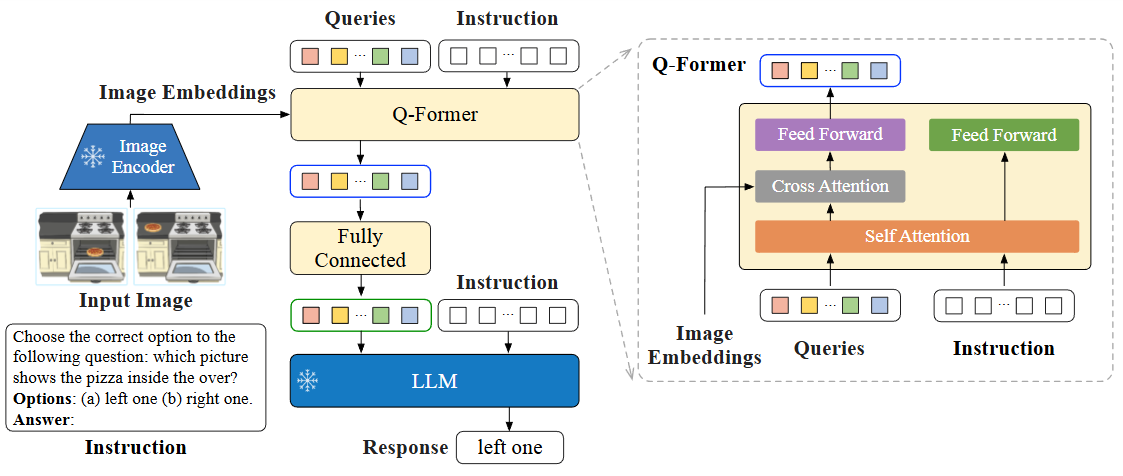
Fig. 26.9 Model architecture of InstructBLIP. The Q-Former extracts instruction-aware visual features from the output embeddings of the frozen image encoder, and feeds the visual features as soft prompt input to the frozen LLM. We instruction-tune the model with the language modeling loss to generate the response. Image from [LLWL24].#
Task |
Instruction Template |
|---|---|
Image Captioning |
|
VQA |
|
VQG |
|
Question: |
|
Question: |
|
Question: |
26.5. Bibliography#
Brian Lester, Rami Al-Rfou, and Noah Constant. The power of scale for parameter-efficient prompt tuning. arXiv preprint arXiv:2104.08691, 2021.
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: bootstrapping language-image pre-training with frozen image encoders and large language models. In International conference on machine learning, 19730–19742. PMLR, 2023.
Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. Blip: bootstrapping language-image pre-training for unified vision-language understanding and generation. In International conference on machine learning, 12888–12900. PMLR, 2022.
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. Advances in neural information processing systems, 2024.
Renze Lou, Kai Zhang, and Wenpeng Yin. Large language model instruction following: a survey of progresses and challenges. Computational Linguistics, pages 1–10, 2024.
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, and et al. Learning transferable visual models from natural language supervision. In International Conference on Machine Learning, 8748–8763. PMLR, 2021.