22. Advanced Prompting Techniques#
22.1. Reasoning-Oriented Prompting#
22.1.1. CoT with Self-Consistency#
Chain-of-thought prompting combined with pre-trained large language models has achieved encouraging results on complex reasoning tasks. [WWS+22] propose a self-consistency strategy to further improve the performance of chain-of-thought prompting. The key idea is that Fig. 22.1:
First we samples a diverse set of reasoning paths
Then we select the most consistent answer by marginalizing out the sampled reasoning paths. Self-consistency is based on the intuition that a complex reasoning problem typically admits multiple different ways of thinking leading to its unique correct answer.
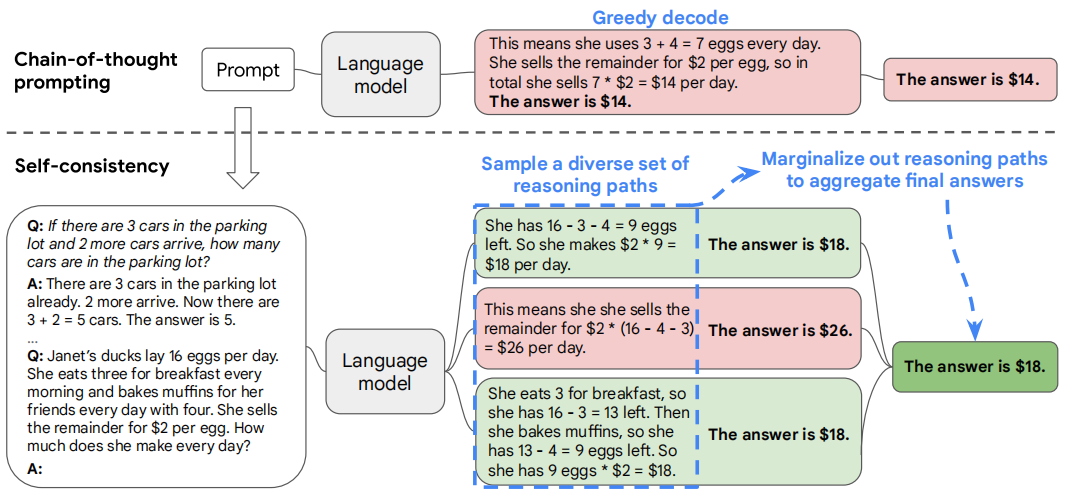
As shown in the following [Fig. 22.2], using over LaMDA-137B, self-consistency (blue) significantly improves accuracy over CoT-prompting with greedy decoding (orange) across arithmetic and commonsense reasoning tasks. Sampling a higher number of diverse reasoning paths consistently improves reasoning accuracy.

Fig. 22.2 The effect of the number of sampled reasoning paths.#
22.1.2. Self-Generated CoT#
When using CoT in prompt writing, we often need experts to manually compose CoT example reasoning steps. Self-Generated CoT aims to automate the CoT examples using LLM itself. The finding is that CoT rationales generated by GPT-4 are longer and provide finer-grained step-by-step reasoning logic. The following examples compare the manually crafted CoT and self-generated CoT Fig. 22.3.

Fig. 22.3 Self-generated CoT demonstration. Comparison of expert-crafted and GPT-4-generated chain-of-thought (CoT) prompts.#
Note that a key challenge with the self-generated CoT rationales are they can be incorrect reasoning chains due to halluciation. This can be mitigated by asking LLM to produce both reasoning chain as well the likelihood answer (similar to two step zero-shot CoT Fig. 21.3). If this answer does not match the ground truth label, then the reasoning sample can be discarded. Note that there can still be cases that incorrect reasoning chain leading to correct answers.
22.1.3. Step Back Prompting#
Complex multi-step reasoning tasks, particularly domain specific reasoning such as Physics and Chemistry remain challenge to LLM. These questions are usually knowledge-intensive question answering, involving many low-level details, thus requiring factual knowledge, multi-hop commonsense reasoning.
For example, a question from chemical physics - What happens to the pressure, P, of an ideal gas if the temperature is increased by a factor of 2 and the volume is increased by a factor of 8 ? would require the understanding the physical principle on gas first, and then perform reasoning to get the answer.
The idea of Step Back prompting [ZMC+23] is inspired by how human approaches these type of taks - humans often step back and do abstractions to arrive at high-level principles to guide the reasoning process [Fig. 22.4].
The prompting involves two steps:
Abstraction: Instead of addressing the question directly, we first prompt the LLM to ask a generic step-back question about a higher-level principle and relevant context, which encourages the model to produce relevant facts and principles.
Reasoning: Grounding on the facts produced in the first stepregarding the high-level concept or principle, the LLM then reason about the solution to the original question.
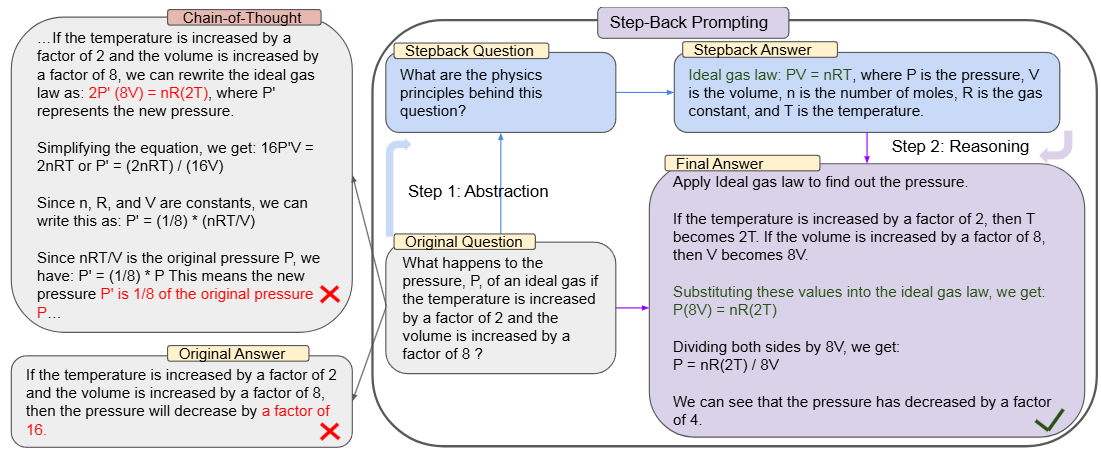
Fig. 22.4 Illustration of Step-Back prompting, which consists of two steps of Abstraction and Reasoning. Here shows an example of MMLU high-school physics where the first principle of Ideal Gas Law is retrieved via abstraction before generating answers. Image from [ZMC+23].#
The following table shows the performance on MMLU tasks, Step-Back prompting shows furhter improvement on CoT prompting.
Method |
MMLU Physics |
MMLU Chemistry |
|---|---|---|
GPT-4 |
\(69.4 \%(2.0 \%)\) |
\(80.9 \%(0.7 \%)\) |
GPT-4 1-shot |
\(78.4 \%(2.4 \%)\) |
\(80.5 \%(1.6 \%)\) |
GPT-4 + CoT |
\(82.9 \%(0.5 \%)\) |
\(85.3 \%(1.0 \%)\) |
GPT-4 + CoT 1-shot |
\(79.3 \%(1.0 \%)\) |
\(82.8 \%(0.5 \%)\) |
GPT-4 + Step-Back |
\(\mathbf{8 4 . 5 \% ( 1 . 2 \% )}\) |
\(\mathbf{8 5 . 6 \% ( 1 . 4 \% )}\) |
22.1.4. Tree of Thoughts#
[YYZ+24]
22.1.5. Program of Thoughts#
[CMWC22]
[GMZ+23]
22.2. Choice Shuffling Ensembling#
Choice shuffling ensembling combines two key ideas to improve prompting effectiveness for multi-choice questions:
Ensembling - combines outputs of multiple model runs to achieve a more robust or accurate result through methods like averaging or majority vote.
Bias mitigation - shuffle the choices can mitigate the position bias that LLM or GPT-4 has (a tendency to favor certain options in multiple choice answers over others regardless of the option content)
With choice shuffling, we shuffle the relative order of the answer choices before generating each reasoning path. We then select the most consistent answer, i.e., the one that is least sensitive to choice shuffling.
Choice shuffling has an additional benefit of increasing the diversity of each reasoning path beyond temperature sampling, thereby also improving the quality of the final ensemble.
22.3. Dynamic In-Context Learning#
In the most common form of in-context learning (also known as few-shot learning),LLM is prompted with a few demonstrations, and produce responses following the task format in the prompt. These few-shot examples used in prompting for a particular task are typically fixed; they are unchanged across test examples.
To achieve the best testing performance, it is necessary that these few-shot examples selected are broadly representative and relevant to a wide distribution of text examples.
In the dynamic few-shot prompting setting, we can select can select different few-shot examples for different task inputs. The selection criterion can be based on the simiarlity to the testing case at hand.
For example, at inference time, given a test question, we re-embed the test sample with the same embedding model used during pre-processing, and utilize kNN to retrieve similar examples from the preprocessed examples.
22.4. Combining Together Example: Med Prompt#
By using advanced prompting techniques, GPT-4 demonstrated significant capabilities in areas involving significant domain knowledge, such as medicine, which challenges the assumption that it requires intensive domain-specific training to match specialist capabilities.
In [NLZ+23], authors carried out a systematic exploration of prompt engineering strategies that significantly enhance GPT-4’s performance in medical question-answering tasks. Medprompt integrates techniques like in-context learning and chain-of-thought reasoning, leading to a 27% reduction in error rate on the MedQA dataset compared to specialist models.
Medprompt employs dynamic few-shot selection, self-generated chain of thought, and choice shuffle ensembling. These techniques collectively contribute to its high performance in medical benchmarks.
An ablation study in the following highlighted the relative contributions of Medprompt’s components.Each technique incrementally improves the model’s performance, with the final accuracy reaching 90.2%. The most significant improvements come from GPT Self-Generated CoT (+3.4%) and the 5x Choice-Shuffle Ensemble Layer (+2.1%).
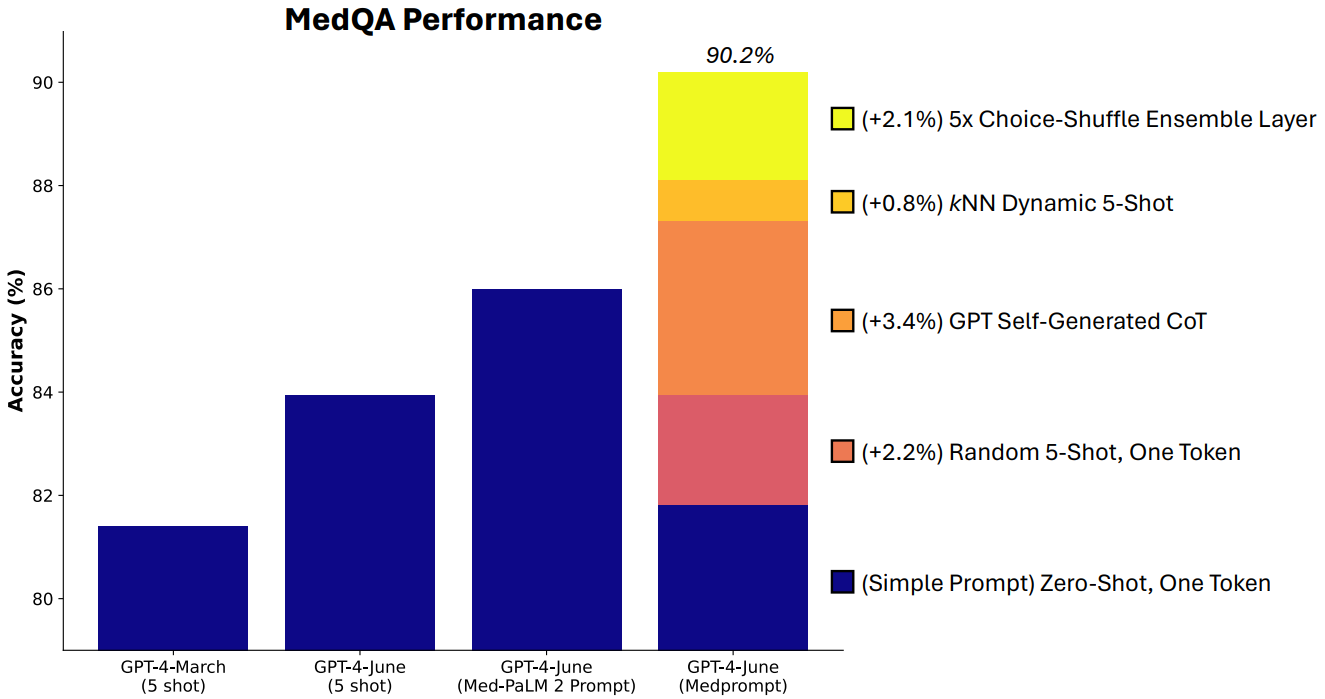
Fig. 22.5 Relative contributions of different components of Medprompt via an ablation study.#
22.5. Self-Refine#
The main idea of SELF-REFINE is to iteratively prompt the same language model to provide feedback on its output and refine the output based on the feedback [Fig. 22.6]. Fig. 22.7 shows the examples for diaglogue improvement and code optimization.
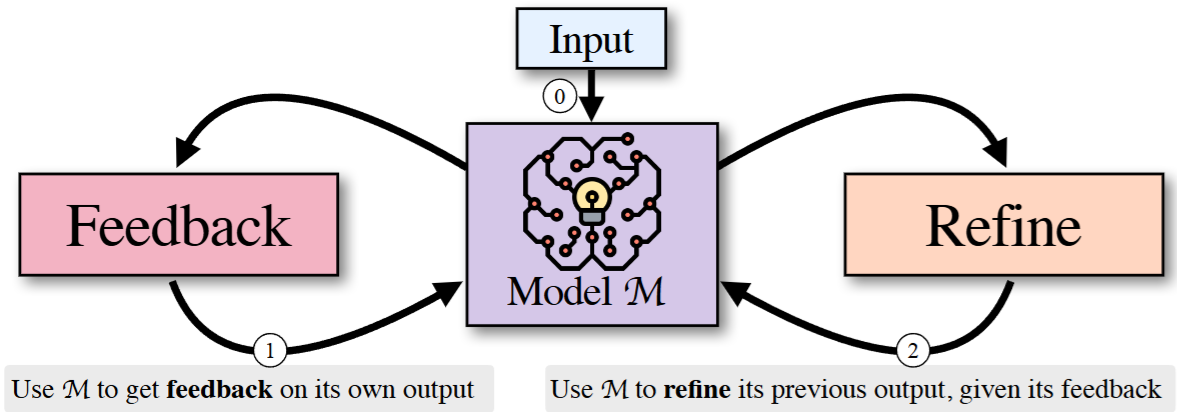
Fig. 22.6 Given an input (step 0), SELF-REFINE starts by generating an output and passing it back to the same model M to get feedback (step 1). The feedback is passed back to M, which refines the previously generated output (step 2). Steps 1 and 2 are iterating until a stopping condition is met. Image from [MTG+24].#
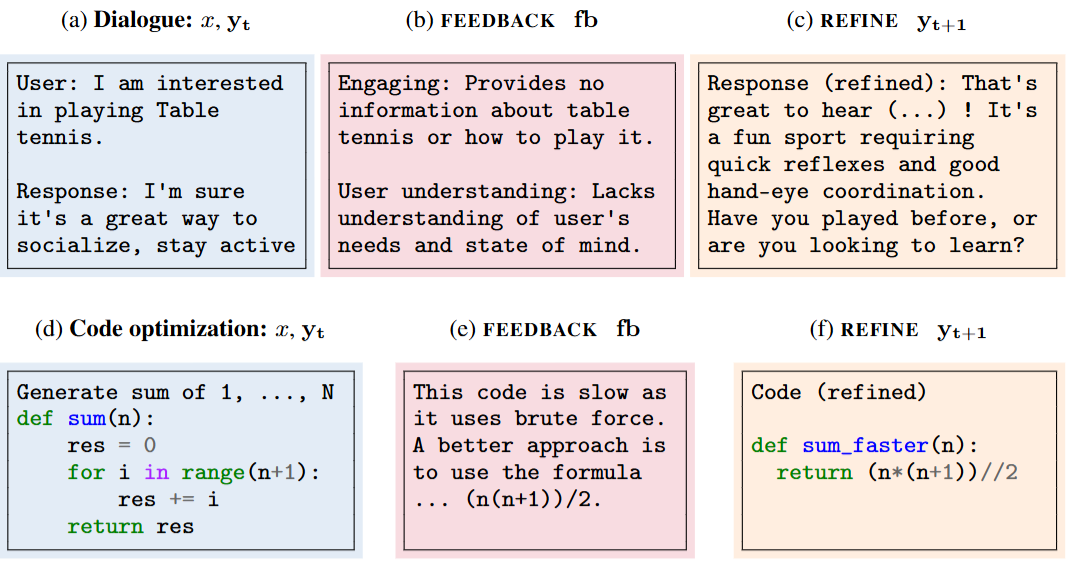
Fig. 22.7 Examples of SELF-REFINE in dialogue improvement (upper) and code optimization (lower). Image from [MTG+24].#
Key findings from evaluating GPT-4 on different tasks:
SELF-REFINE consistently improves over across all tasks.
SELF-REFINE is very effective in langugage generation tasks, like improving generation quality and diversity. For example, in constrained generation task, where the model is asked to generate a sentence containing up to 30 given concepts. For this task, it is easy to miss some of the concepts on the first attempt, and SELF-REFINE allows the model to fix these mistakes subsequently.
For reasoning-heavy tasks like code optimization and math reasoning, the improvement from self-refinement is very limited. Unlike language gneeration task, the model is not well-train to provide correct feedback on reasoning tasks. Studies from [CKB+21, HCM+23] suggested that external feedbacks or a separately trained verifier is needed to guide the model to generate improved results.
Task |
Base |
+SELF-REFINE |
|---|---|---|
Sentiment Reversal |
3.8 |
\(\mathbf{3 6 . 2}(\uparrow 32.4)\) |
Dialogue Response |
25.4 |
\(\mathbf{7 4 . 6}(\uparrow 49.2)\) |
Code Optimization |
27.3 |
\(\mathbf{3 6 . 0}(\uparrow 8.7)\) |
Code Readability |
27.4 |
\(\mathbf{5 6 . 2}(\uparrow 28.8)\) |
Math Reasoning |
92.9 |
\(\mathbf{9 3 . 1}(\uparrow 0.2)\) |
Acronym Generation |
30.4 |
\(\mathbf{5 6 . 0}(\uparrow 25.6)\) |
Constrained Generation |
15.0 |
\(\mathbf{4 5 . 0}(\uparrow 30.0)\) |
22.6. Bibliography#
Wenhu Chen, Xueguang Ma, Xinyi Wang, and William W Cohen. Program of thoughts prompting: disentangling computation from reasoning for numerical reasoning tasks. arXiv preprint arXiv:2211.12588, 2022.
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, and others. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021.
Luyu Gao, Aman Madaan, Shuyan Zhou, Uri Alon, Pengfei Liu, Yiming Yang, Jamie Callan, and Graham Neubig. Pal: program-aided language models. In International Conference on Machine Learning, 10764–10799. PMLR, 2023.
Jie Huang, Xinyun Chen, Swaroop Mishra, Huaixiu Steven Zheng, Adams Wei Yu, Xinying Song, and Denny Zhou. Large language models cannot self-correct reasoning yet. arXiv preprint arXiv:2310.01798, 2023.
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, and others. Self-refine: iterative refinement with self-feedback. Advances in Neural Information Processing Systems, 2024.
Harsha Nori, Yin Tat Lee, Sheng Zhang, Dean Carignan, Richard Edgar, Nicolo Fusi, Nicholas King, Jonathan Larson, Yuanzhi Li, Weishung Liu, and others. Can generalist foundation models outcompete special-purpose tuning? case study in medicine. arXiv preprint arXiv:2311.16452, 2023.
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. arXiv preprint arXiv:2203.11171, 2022.
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. 2023. URL: https://arxiv.org/abs/2203.11171, arXiv:2203.11171.
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: deliberate problem solving with large language models. Advances in Neural Information Processing Systems, 2024.