21. Basic Prompting#
21.1. Base LLM vs Instructed LLM#
The purpose of presenting few-shot examples in the prompt is to explain our intent to the model; in other words, describe the task instruction to the model in the form of demonstrations. However, few-shot can be expensive in terms of token usage and restricts the input length due to limited context length. So, why not just give the instruction directly?
Instructed LM (e.g. InstructGPT, natural instruction) finetunes a pretrained model with high-quality tuples of (task instruction, input, ground truth output) to make LM better understand user intention and follow instruction. RLHF (Reinforcement Learning from Human Feedback) is a common method to do so. The benefit of instruction following style fine-tuning improves the model to be more aligned with human intention and greatly reduces the cost of communication.
When interacting with instruction models, we should describe the task requirement in details, trying to be specific and precise and avoiding say “not do something” but rather specify what to do.
21.2. Zero-shot prompt#
A zero-shot prompt for LLM is a technique where the model is asked to perform a task or answer a question without providing examples or any specific training for that particular task. The model relies solely on its pre-existing knowledge and general language understanding to generate a response.
For example, in zero shot text classification (see the following), we provide the model with a prompt and a sequence of text that describes what we want our model to do, in natural language. Zero-shot classification excludes any examples of the desired task being completed. This differs from single or few-shot classification, as these tasks include a single or a few examples of the selected task.
Example 21.1 (Zero shot prompt for movie review sentiment classification)
Prompt: Classify the sentiment of the following movie review as positive, negative, or neutral:
Review: ‘The visuals were stunning and the action sequences kept me on the edge of my seat. However, the plot was thin and the characters lacked depth. Overall, it was an entertaining but forgettable experience.
Response: The sentiment of the movie review can be classified as neutral. While the reviewer mentions positive aspects such as “stunning visuals” and “action sequences,” they also highlight significant drawbacks like a “thin plot” and “characters lacked depth.” The conclusion that it was an “entertaining but forgettable experience” suggests a mixed sentiment, leading to a neutral overall impression.
Besides the above demonstrated classification text, LLM can accomplish a wide rangle of straight forward tasks, as shown in the following.
Example 21.2 (Zero shot prompt for text extracting)
Prompt: Extract the title, h1, and body text from the following HTML
Document:
<head><title>A simple page</title></head><body><h1>Hello World</h1><p>This is some text in a simple html page.</p></ body>
Response: Title: A simple page
H1: Hello World
Body text: This is some text in a simple html page.
Example 21.3 (Zero shot prompt for programming task)
Prompt: Write a python code to compute the 50th element in the Fibonacci sequence.
Response: Certainly! Here’s a Python code snippet that computes the 50th element in the Fibonacci sequence:
def fibonacci(n):
if n == 0: return 0
elif n == 1: return 1
else:
a, b = 0, 1
for _ in range(2, n + 1):
a, b = b, a + b
return b
# Compute the 50th element in the Fibonacci sequence
fibonacci_50th = fibonacci(50)
print(fibonacci_50th)
When you run this code, it will calculate and print the 50th element in the Fibonacci sequence, which is 12,586,269,025.
On one hand, zero shot learning offers flexibility to address a wide range of tasks without the need to construct task specific examples.
On the other hand, as LLM’s pretrained knowledge is the solely relied on to generate the response, it can have variable performance across the tasks. Specifically, the effectiveness can vary depending on the complexity of the task and how well it aligns with the model’s pre-trained knowledge.
21.3. Few-shot and in-context learning#
Few-shot learning is a technique where an LLM is given a small number of examples (typically 2-5) to guide its understanding of a task before it’s asked to perform that task on new, unseen data. This approach interpolates between zero-shot learning (no examples) and fine-tuning (extensive task-specific training).
In the few-shot example, the model has some context for how to approach the task, potentially leading to more accurate and consistent results compared to the zero-shot approach.
Example 21.4
Pormpt: Classify the sentiment of movie reviews as positive, negative, or neutral.
Examples:
“A masterpiece of cinema with stunning visuals and a gripping plot.” Sentiment: Positive
“Terrible acting and a nonsensical story. Avoid at all costs.” Sentiment: Negative
“It was okay. Nothing special, but not bad either.” Sentiment: Neutral
Now classify this review: “The special effects were amazing, but the story was boring.” Sentiment:
Response: Neutral
In the following, we summarize the key differences between zero-shot and few-shot learning.
Zero-shot Prompt
No task-specific examples: The model is not provided with any examples of the task it’s being asked to perform. The LLM uses its broad understanding of language and concepts to interpret and respond to the prompt.
Flexibility: This approach allows LLMs to attempt a wide range of tasks without providing examples.
Variable performance: The effectiveness can vary depending on the complexity of the task and how well it aligns with the model’s pre-trained knowledge.
Few-shot Prompt
Limited examples: The model is provided with a small set of examples demonstrating the desired task or output format.
Improved task-specific performance: Few-shot learning often leads to better results than zero-shot for specific tasks.
Less flexibility: It allows for quick adaptation to new tasks without the need for model retraining. But task specific examples are needed.
21.4. Chain-of-Thought (CoT) Prompting#
Chain of Thought (CoT) prompting [WWS+22] is a technique used with Large Language Models (LLMs) to enhance their problem-solving capabilities, especially for complex tasks requiring multi-step reasoning. The motivation behind CoT prompting is to mimic human-like step-by-step thinking processes, addressing the limitation of LLMs in handling tasks that require intermediate logical steps.
The key idea is to prompt the model to “think aloud” by breaking down its reasoning into explicit steps, often by providing examples of such step-by-step reasoning in the prompt. This approach offers several benefits: it improves the model’s performance on complex tasks, increases transparency in the decision-making process, and allows for easier error detection and correction.
CoT prompting can help LLMs tackle problems that were previously challenging, such as multi-step mathematical or logical reasoning tasks.
However, this method also has drawbacks: it can significantly increase the length of prompts and responses, potentially leading to higher computational costs and token usage. Moreover, the effectiveness of CoT prompting can vary depending on the specific task and the quality of the examples provided, and it may not always yield improvements for simpler tasks where direct answers suffice.
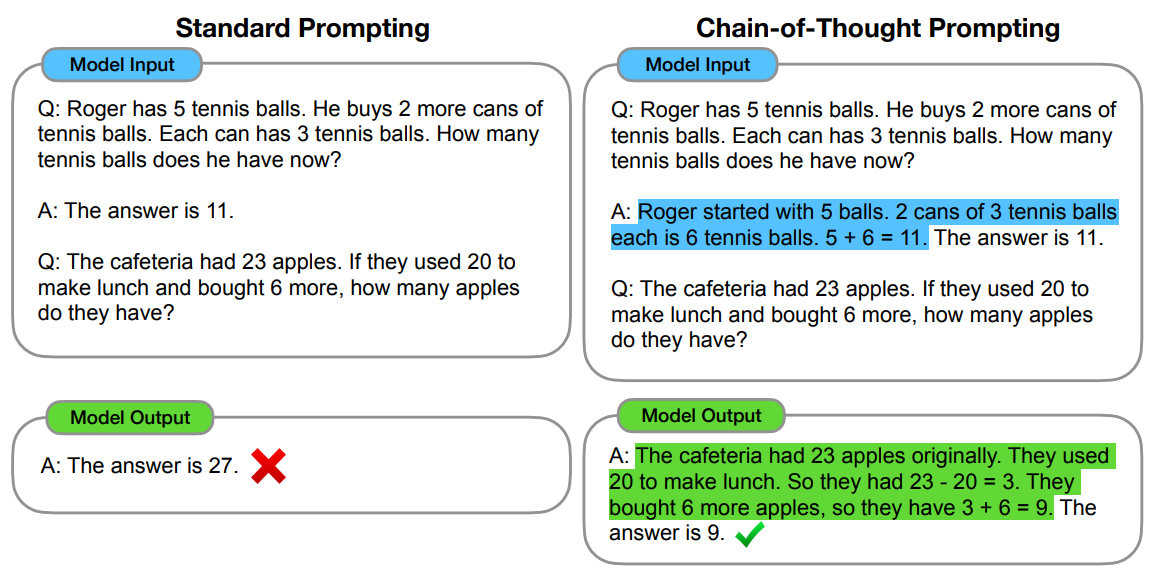
Fig. 21.1 COT example.#
The idea of COT can be generalize to different tasks, as shown in the following.

Fig. 21.2 More COT examples for different tasks.#
The classically CoT prompting requires CoT few-shot demonstration, a further simplification is to use sentence like “Let’s think step by step” to encourage the model to directly produce a reasoning chain before generating the final answer[KGR+22]. This approach is illustrated as the following.

Fig. 21.3 Comparison of few-shot CoT and zero-shot CoT#
MultiArith |
GSM8K |
|
|---|---|---|
Zero-Shot |
17.7 |
10.4 |
Few-Shot (2 samples) |
33.7 |
15.6 |
Few-Shot (8 samples) |
33.8 |
15.6 |
Zero-Shot-CoT |
78.7 |
40.7 |
Few-Shot-CoT (8 samples) |
93.0 |
48.7 |
Zero-Plus-Few-Shot-CoT (8 samples) |
92.8 |
51.5 |
21.5. Bibliography#
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. Large language models are zero-shot reasoners. arxiv.org/abs/2205.11916, 2022.
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Ed Chi, Quoc Le, and Denny Zhou. Chain of thought prompting elicits reasoning in large language models. ArXiv:2201.11903, 2022.