17. Llama Series#
17.1. Llama 1#
Llama-1 is first open-source model coming from Meta [TLI+3a]. Compared to GPT, the following changes have been made to enhance training stability and model performance:
Pre-RMSNorm is used as a layer normalization method
SwiGLU is used as the activation function
RoPE is used as position encoding to enhance long sequence modeling ability
Llama-1 training was using next-token-prediction self-supervised learning on 1.4T token, as a comparison GPT-3 was roughly trained on 500B tokens. These pre-training data are mixed from multiple sources and are all public data. The data volume and sampling ratio of each source are shown in the table below
Dataset |
Sampling prop. |
Epochs |
Disk size |
|---|---|---|---|
CommonCrawl |
\(67.0 \%\) |
1.10 |
3.3 TB |
C4 |
\(15.0 \%\) |
1.06 |
783 GB |
Github |
\(4.5 \%\) |
0.64 |
328 GB |
Wikipedia |
\(4.5 \%\) |
2.45 |
83 GB |
Books |
\(4.5 \%\) |
2.23 |
85 GB |
ArXiv |
\(2.5 \%\) |
1.06 |
92 GB |
StackExchange |
\(2.0 \%\) |
1.03 |
78 GB |
Llama-1 is considered as a big milestone as it shows that
It is possible to train state-of-the-art models using publicly available datasets exclusively,
To optimize for inference time efficiency, one can consider training a small model with large amount of data (e.g., training time optimal effiency would suggest training on 10B model on 200B tokens based on [HBM+22])
Evaluting on benchmarks including standard common sense reasoning, closed QA, reading comprehension, mathematical reasoning, code generation, and language understanding, LLaMA-1 13B outperforms GPT-3 (175B) on most benchmarks, and LLaMA-1 65B is competitive with the best models, Chinchilla-70B and PaLM-540B.
17.2. Llama 2#
17.2.1. Overview#
Contribution from Llama-2 [TMS+3b] are two-folds:
Improvement on pretraining, with a slight change of model architecture:
Llama-2 pre-training used 2T data tokens from publicly available sources, with 40% more data compared to Llama-1.
Adopt GQA for larger sizes (i.e., 34B, 70B) to reduce the overall parameter quantity.
Double the context length from 2k to 4k
Concentrated improvement on post-pretraining, including SFT, iterative reward modeling, and RLHF to enhance the model’s ability in diagolue and instruction-following safely.
The improvement of pretraining for Llama-2 vs Llama-1 is summarized in the following table. Essentially, additional data quantity and improved data quality bring additional gain across all benchmarks.
Model |
Size |
Code |
Commonsense Reasoning |
World Knowledge |
Reading Comprehension |
Math |
MMLU |
BBH |
AGI Eval |
|---|---|---|---|---|---|---|---|---|---|
LLAMA 1 |
13B |
18.9 |
66.1 |
52.6 |
62.3 |
10.9 |
46.9 |
37.0 |
33.9 |
33B |
26.0 |
70.0 |
58.4 |
67.6 |
21.4 |
57.8 |
39.8 |
41.7 |
|
65B |
30.7 |
70.7 |
60.5 |
68.6 |
30.8 |
63.4 |
43.5 |
47.6 |
|
LLAMA 2 |
7B |
16.8 |
63.9 |
48.9 |
61.3 |
14.6 |
45.3 |
32.6 |
29.3 |
13B |
24.5 |
66.9 |
55.4 |
65.8 |
28.7 |
54.8 |
39.4 |
39.1 |
|
34B |
27.8 |
69.9 |
58.7 |
68.0 |
24.2 |
62.6 |
44.1 |
43.4 |
|
70B |
37.5 |
\(\mathbf{7 1 . 9}\) |
\(\mathbf{6 3 . 6}\) |
\(\mathbf{6 9 . 4}\) |
\(\mathbf{3 5 . 2}\) |
\(\mathbf{6 8 . 9}\) |
\(\mathbf{5 1 . 2}\) |
\(\mathbf{5 4 . 2}\) |
In the following, we review key process for pretraining and post-training alignment of LLama2 model to human preference [Fig. 17.1]. Specifially, LLama2 alignment consists of the following iterative steps:
Collecting human preference data
Training reward model to predict human preference, iteratively
Using reward model to guide model improvement via rejection sampleing SFT and RLHF
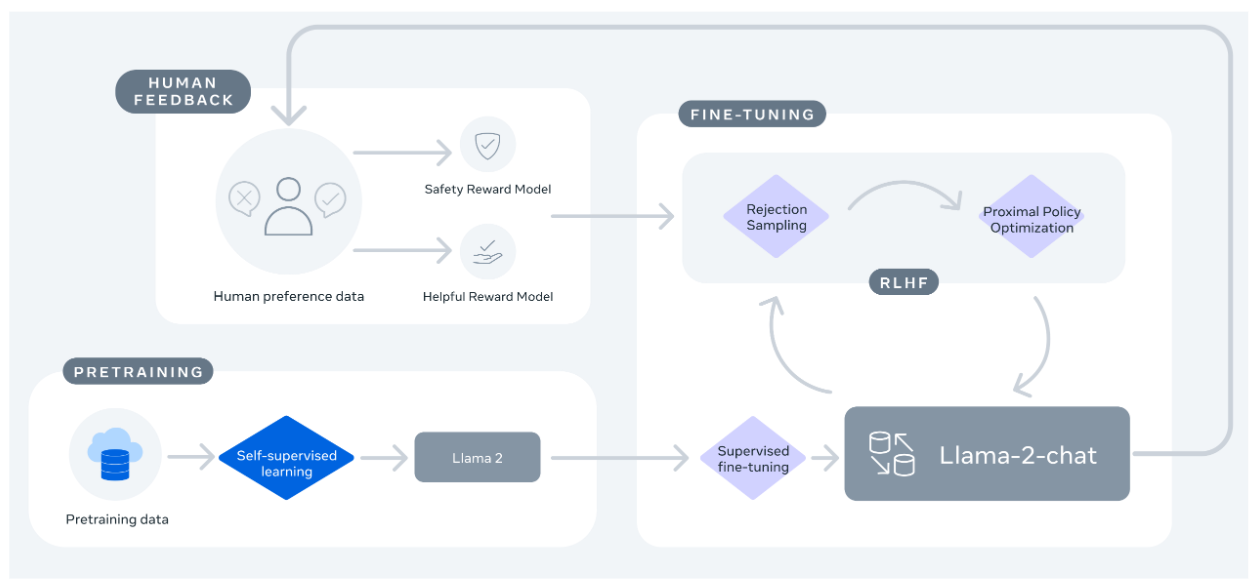
Fig. 17.1 Overview of iterative alignment process in LLama2 after pretraining and supervised fine-tuning. Note that reward model is also iteratively updated the ensure the reward modeling remain within distribution. Image from [TLI+3a].#
17.2.2. Finetuning and Alignment#
17.2.2.1. Supervised Fine-Tuning#
The pretrained model was first supervised fine-tuned before further RLHF. The fine-tuned data is focused on improving the model’s helpfulness and safety by providing positive examples. The quality and diversty is more important than quanity - data in the order of tens of thousands were sufficient for high quality results.

Fig. 17.2 Example of a helpfulness (top) and safety (bottom) training data for SFT. Image from [TLI+3a].#
17.2.2.2. Preference Data Collection#
To collect comprehensive human feedback data, the Meta team considered both open-source and in-house data.
For open-source data, they used datasets from Anthropic, OpenAI, etc., containing approximately 1.50M human preference data points. These data primarily focused on two aspects: safety and usefulness, where safety refers to whether the model produces unsafe outputs, and usefulness refers to the extent to which the model’s outputs can address human requests.
For in-house data, they hired human annotator to produce both safety and usefulness labels on about ~1.4M data points. Annotators first wrote an input prompt, then selected outputs from two models based on corresponding criteria to serve as positive and negative examples.
Note that these preference data is used in reward model training. In the iterative alignment process of LLaMA-2, the distribution of model-generated content would change, leading to degradation of the reward model. To prevent this phenomenon, new annotated data needed to be collected during the training process to retrain the reward model.
17.2.2.3. Reward Modeling#
After collecting human feedback data, reward models are trained based on the collected data, which are then used to provide on-the-fly feedback signal in subsequent training processes. To obtain more detailed reward signals, data related to safety tasks and usefulness tasks are used separately to train two reward models.
To better help reward models distinguish the differences between positive and negative examples, a margin \(m(y^+, y^-)\) is added between human preference between positive and negative examples. The optimized training objective for the reward model is shown in the following equation:
where \(x\), \(y^+\), and \(y^-\) represent the model input, positive example, and negative example respectively. Naturally, we use a large margin for pairs with distinct responses, and a smaller one for those with similar responses
17.2.2.4. Iterative Alignment#
LLama-2 took a iterative approch to align the LLM to human preference. As the alignment progresses, we are able to train better reward models and collect more prompts. We therefore can train successive versions for RLHF models, referred to here as RLHF-V1, …, RLHF-V5. Two alignment algorithms are explored:
SFT with Rejection Sampling. \(K\) outputs from the model (might include previous version model) and select the best candidate with the reward model. The highest rewarded output is collected to perform SFT.
Proximal Policy Optimization (PPO) as in the standard RLHF literature.
Until RLHF (V4), only Rejection Sampling SFT is only used, and after that, two algorithms were combined sequentially - applying PPO on top of the resulted Rejection Sampling checkpoint before sampling again.
17.3. Llama 3#
Llama-3 uses the same model architecture of Llama-2. The key improvement are summarized below.
Training data: Llama-3 was trained on 15T tokens (~8 times of the ~2T tokens used in Llama2) to enhance language understanding, coding, and reasoning. Training data were carefully selected, with good quality by leveraging Llama2 model.
Coding and reasoning: The code training data has been expanded 4 times, significantly improving the model’s performance in coding and logical reasoning abilities.
Large context window: Llama 3 supports condex window of 128k, whereas Llama 2 only supports context window of 4k.
Multi-lingual support: The training data of LLaMA-3 includes over 5% non-English tokens from more than 30 languages, which significantly improves its multilingual processing capabilities
Multimodality support: By adding multi-modality adapters, one can leverage Llama 3 to take inputs from images, videos, and audio in addition to text.
Scale and performance: Llama 3 has three model sizes: 8B, 70B, 405B; Llama 3 achieved competitive performances among models of similar sizes [Fig. 17.3].
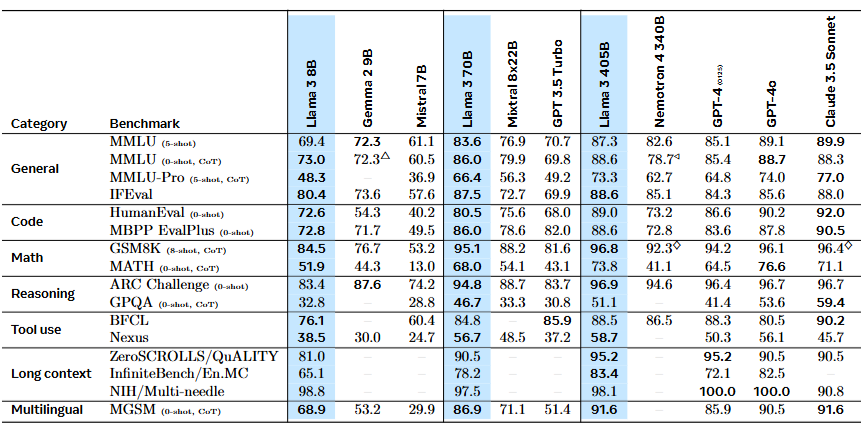
Fig. 17.3 Comparison of the FT Llama3 model with other models across a diverse benchmarks. Image from [DJP+24].#
The training Llama-3 has two phases:
Pre-training phase, which conducts next-token-prediction task on large-scale data. Particularly a series of scaling laws was developed to guide the selection of data composition.
Post-training phase, which invovles using SFT, rejection sampling, RLHF, and DPO for multi-rounds to improve the alignment outcome.
17.3.1. Pretraining#
Critical factors affecting pretraining results include:
Data quanity, quality, and distribution. Meta has developed a series of data filtering pipelines to ensure data quality, including heuristic filters, NSFW filters, semantic duplicate data removal technology, and text classifiers for predicting data quality. The effectiveness of these tools benefits from the performance of previous versions of Llama, especially in identifying high-quality data.
Optimal model size and data mixture with given the pre-training compute budget - undertraining a larger model or overtraining a small model will yield inferior results[Fig. 17.4]. Scaling laws were first developped to establish the relationship between downstream performance and compute budget and then used to identify optimal model size and data mixture.
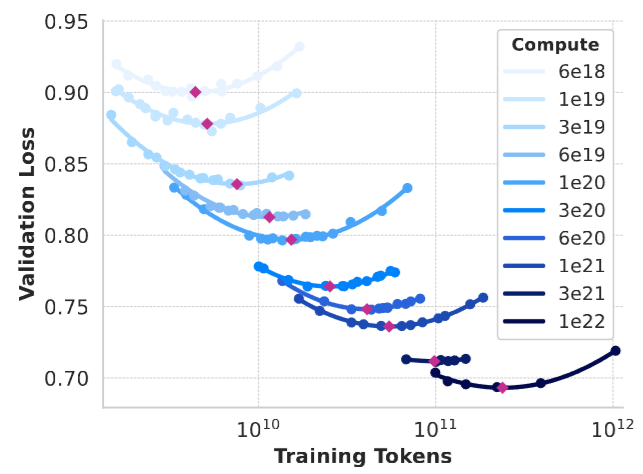
Fig. 17.4 Under different compute budget contraints (different curves), different model sizes (dots on curves) can achieve different performance. Red points at parabola minimums are correponding optimal model size with given budgets. Image from [DJP+24].#
The long-context extension was implemented via a multi-stage training fashion: Llama 3 was first pretrained using a context window of 8K tokens. This standard pre-training stage is followed by a continued pre-training stage that increases the supported context window to 128K tokens. This long-context pre-training stage was performed using approximately 800B training tokens.
17.3.2. Post-Training#
The post-training workflow in summarized in Fig. 17.5, with the following key steps:
Collection of task prompts, completions, and human annotations.
Reward modeling to train a reward model based on pairwise ranking loss.
Rejection sampling to obtain high-quality positive examples.
Iterative improvement via SFT and DPO
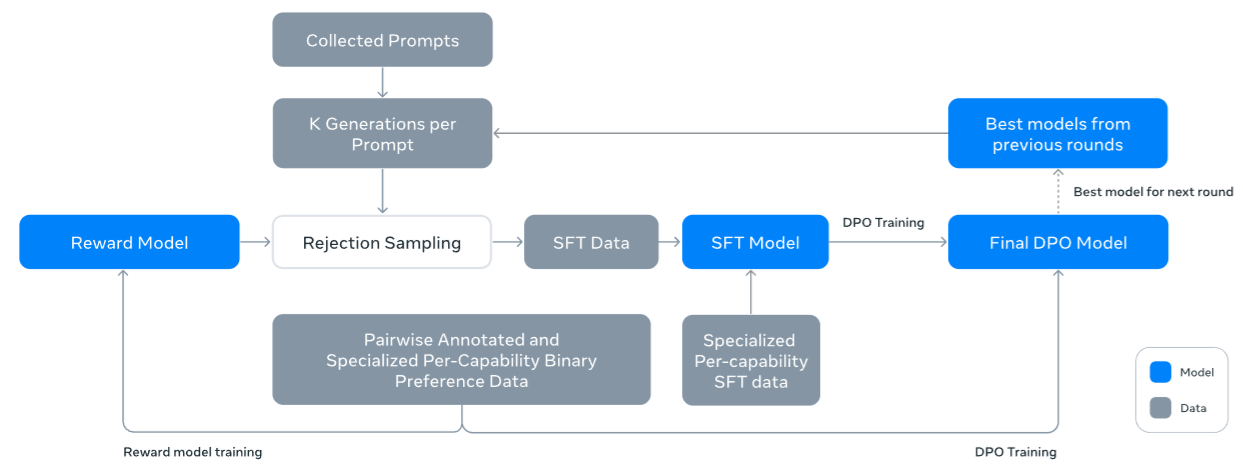
Fig. 17.5 Illustration of the overall post-training approach for Llama 3. The post-training strategy involves rejection sampling, supervised finetuning, and direct preference optimization. Image from [DJP+24].#
Training data for post-training consists of SFT data and preference data.
SFT data consists of following sources:
High quality responses from rejection-sampling - An LLM model checkpoint is used to generate K (between 10 and 30) responses for each prompt, and then scores these answers using the Reward Model to select the highest-scoring and best-performing answer.
Synthetic data was used to handle issues in code generation, including difficulty in following instructions, code syntax errors, incorrect code generation, and difficulty in fixing bugs.
Preference data follows a similar annotation procedure in Llama-2. A new step include encouraging annotators to further improve the prefered responses. A small portion of data have following preference rank:
SFT uses a standard cross entropy loss only on the target tokens, while masking out loss on prompt tokens.
DPO from LLaMA3 has the following improvements:
In DPO loss, formating related tokens (including the header and termination tokens) are masked out to stabilize DPO training. These tokens barely contribute to the score of the responses, yet they affects the preference loss computation.
Regularizated DPO: an additional negative log likelihood loss of the chosen response was added to further stabilize DPO training by maintaining the generated expected format and preventing the decrease of log probability of the chosen response. See more details in DPO-Positive and Regularized DPO.
17.4. Bibliography#
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, and others. The llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024.
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, and et al. Training compute-optimal large language models. ArXiv:2203.15556, 2022.
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, and et al. LLaMA: open and efficient foundation language models. ArXiv:2302.13971, 2023a.
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, and et al. LLaMA 2: open foundation and fine-tuned chat models. ArXiv:2307.09288, 2023b.