18. DeepSeek Series#
18.1. DeepSeek Math#
18.1.1. Overview#
DeepSeekMath-7B [SWZ+24] is a task-adapted model from DeepSeek-Coder base model [GZY+24]. It was continuously pretrained DeepSeek-Coder-Base-v1.5 7B with 120B math-related tokens sourced from Common Crawl, together with natural language and code data. Desipte its small size, it achieves competitive performance on a broad-range of math benchmarks [].
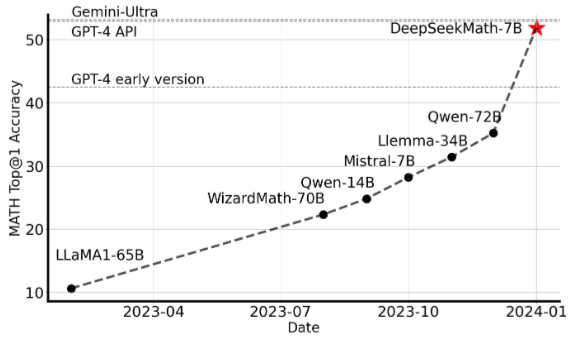
Fig. 18.1 Top1 accuracy of open-source models on the competition-level MATH benchmark. Image from [SWZ+24]#
The key technical highlights of DeepSeek Math model are:
The extraction curation of large-scale math related training data from publicly available web data.
The introduction of Group Relative Policy Optimization (GRPO), a computation-efficient variant of PPO algorithm,
18.1.2. Data Curation#
DeepSeek team created the DeepSeekMath Corpus, a large-scale high-quality pre-training corpus comprising 120B math tokens. This dataset is extracted from the publically available Common Crawl (CC) and provides a compelling evidience existing public data contain trememendous valuable information for math-oriented training.
The data curation process is visualied in Fig. 18.2, with the following key steps:
First use a high-quality MathSeed corpus as the seed corpus to train a fastText classifier.
The fastText classifier is then used to select math-related corpus from the Common Crawl.
Iteratively (~3 rouns) adding more positive example in the seed corpus to train better classifier
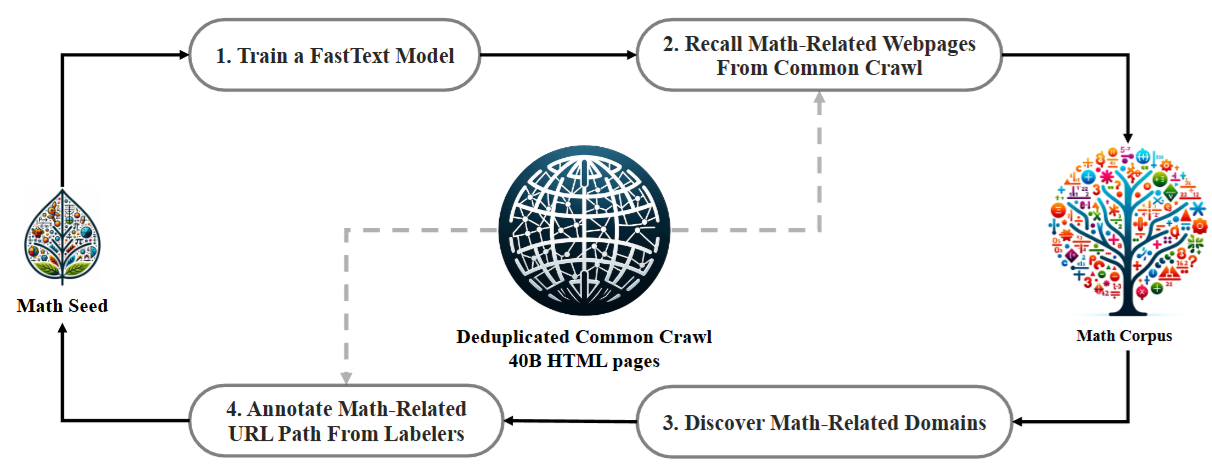
Fig. 18.2 An iterative pipeline that collects mathematical web pages from Common Crawl. Image from [SWZ+24]#
The resulting DeepSeekMath Corpus is of high quality, covers multilingual mathematical content, and is the largest in size.
To validate the quality of the DeepSeekMath corpus and compare with other open sourced math training corpus, validation experiments are carried out in the following manner:
First train a 1.3B general pre-trained language model on the DeepSeekMath corpus.
Then separately train a model on each mathematical corpus for 150B tokens.
The evaluation of the trained model using few-shot CoT prompting is summarized in the following:
Math Corpus |
Size |
GSM8K |
MATH |
|---|---|---|---|
No Math Training |
N/A |
2.9% |
3.0% |
MathPile |
8.9B |
2.7% |
3.3% |
OpenWebMath |
13.6B |
11.5% |
8.9% |
Proof-Pile-2 |
51.9B |
14.3% |
11.2% |
DeepSeekMath Corpus |
120.2B |
23.8% |
13.6% |
Clearly, compared to existing math corpus, training on the high-quality and large-scale DeepSeekMath Corpus can boost math skills signficantly.
18.1.3. Pretraining#
DeepSeekMath-Base 7B was initialized with DeepSeek-Coder-Base-v1.5 7B and trained on for 500B tokens with next-token prediction task. The training data has the composition:
Data Type |
Percentage |
|---|---|
DeepSeekMath Corpus |
56% |
AlgebraicStack |
4% |
arXiv |
10% |
Github code |
20% |
natural language data |
10% |
The pre-trained base 7B model and other open-sourced model were assessed from the following aspects using CoT prompting:
the ability to produce self-contained mathematical solutions without relying on external tools
the ability to solve mathematical problems using tools
the ability to conduct formal theorem proving
The evalution results of self-contained math skills is summarized in the following. The result indicates that the number of parameters is not the only key factor in mathematical reasoning capability.** A smaller model pre-trained on high-quality data could achieve strong performance as well**. The evaluation of tool-using and theorem proving show similar trends.
Model |
Size |
English Benchmarks |
Chinese Benchmarks |
||||||
|---|---|---|---|---|---|---|---|---|---|
GSM8K |
MATH |
OCW |
SAT |
MMLU STEM |
CMATH |
Gaokao MathCloze |
Gaokao |
||
Mistral |
7B |
40.3% |
14.3% |
9.2% |
71.9% |
51.1% |
44.9% |
5.1% |
23.4% |
Llemma |
7B |
37.4% |
18.1% |
6.3% |
59.4% |
43.1% |
43.4% |
11.9% |
23.6% |
Llemma |
34B |
54.0% |
25.3% |
10.3% |
71.9% |
52.9% |
56.1% |
11.9% |
26.2% |
DeepSeekMath-7B-Base |
64.2% |
36.2% |
15.4% |
84.4% |
56.5% |
71.7% |
20.3% |
35.3% |
Additional ablation study in the pretraining process shows that code training benefits program-aided mathematical reasoning in a two-stage training setting where first stage consists of code training and second stage consists of math training.
18.1.4. Post-Training: SFT and RL#
After pre-training, SFT and RL were used to further improved DeepSeekMath-Base with data containing chain-of-thought, program-of-thought, and tool-integrated reasoning. The total number of training examples is 776K. Specifically,
English mathematical datasets covers diverse fields of mathematics, e.g., algebra, probability, number theory, calculus, and geometry. For example, GSM8K and MATH problems with toolintegrated solutions, and a subset of MathInstruct [YQZ+23] and Lila-OOD [MFL+22] where problems are solved with CoT or PoT (program of thoughts).
Chinese mathematical datasets include Chinese K-12 mathematical problems spanning 76 sub-topics such as linear equations, with solutions annotated in both CoT and toolintegrated reasoning format.
After SFT, RL is furhter applied on DeepSeekMath-Instruct 7B. The training data of RL (using GRPO, see Group Relative Policy Optimization (GRPO) for more details) are chain-ofthought-format questions related to GSM8K and MATH from the SFT data, which consists of around 144K questions. Reward model is trained using methods introduced in [WLS+23].
The following table summarized model performance on selected math benchmarks.
Applying SFT can signficantly boost the performance on the base model.
Applying RL can further improve the instructed model - DeepSeekMath-RL 7B beats all opensource models from 7B to 70B, as well as the majority of closed-source models.
Although DeepSeekMath-RL 7B is only further trained on chain-of-thought-format instruction tuning data of GSM8K and MATH, it improves over DeepSeekMath-Instruct 7B on all benchmarks, indiciating math reasoning ability is transferable.
Model |
Size |
English Benchmarks |
Chinese Benchmarks |
||
|---|---|---|---|---|---|
GSM8K |
MATH |
MGSM-zh |
CMATH |
||
Gemini Ultra |
- |
94.4% |
53.2% |
- |
- |
GPT-4 |
- |
92.0% |
52.9% |
- |
86.0% |
Qwen |
72B |
78.9% |
35.2% |
- |
- |
DeepSeekMath-Base |
7B |
64.2% |
36.2% |
- |
71.7% |
DeepSeekMath-Instruct |
7B |
82.9% |
46.8% |
73.2% |
84.6% |
DeepSeekMath-RL |
7B |
88.2% |
51.7% |
79.6% |
88.8% |
18.2. DeepSeek Reasoning Models#
18.2.1. DeepSeek-R1-Zero#
DeepSeek Team explore the potential of LLMs to develop reasoning capabilities without any supervised data, focusing on their self-evolution through a pure reinforcement learning process. The resulting model is named as DeepSeek-R1-Zero.
Specifically, DeepSeek-R1-Zero starts with DeepSeek-V3-Base as the base model and employ a single-stage GRPO reinforcement learning (see Group Relative Policy Optimization (GRPO)) to improve model’s reason ability [Fig. 18.3]. The reward signal consists of two types of rewards:
Accuracy rewards: The accuracy reward model evaluates whether the response is correct. (for math and coding problems, the result is deterministic)
Format rewards: Encourage model to put thinking process between
<think></think>
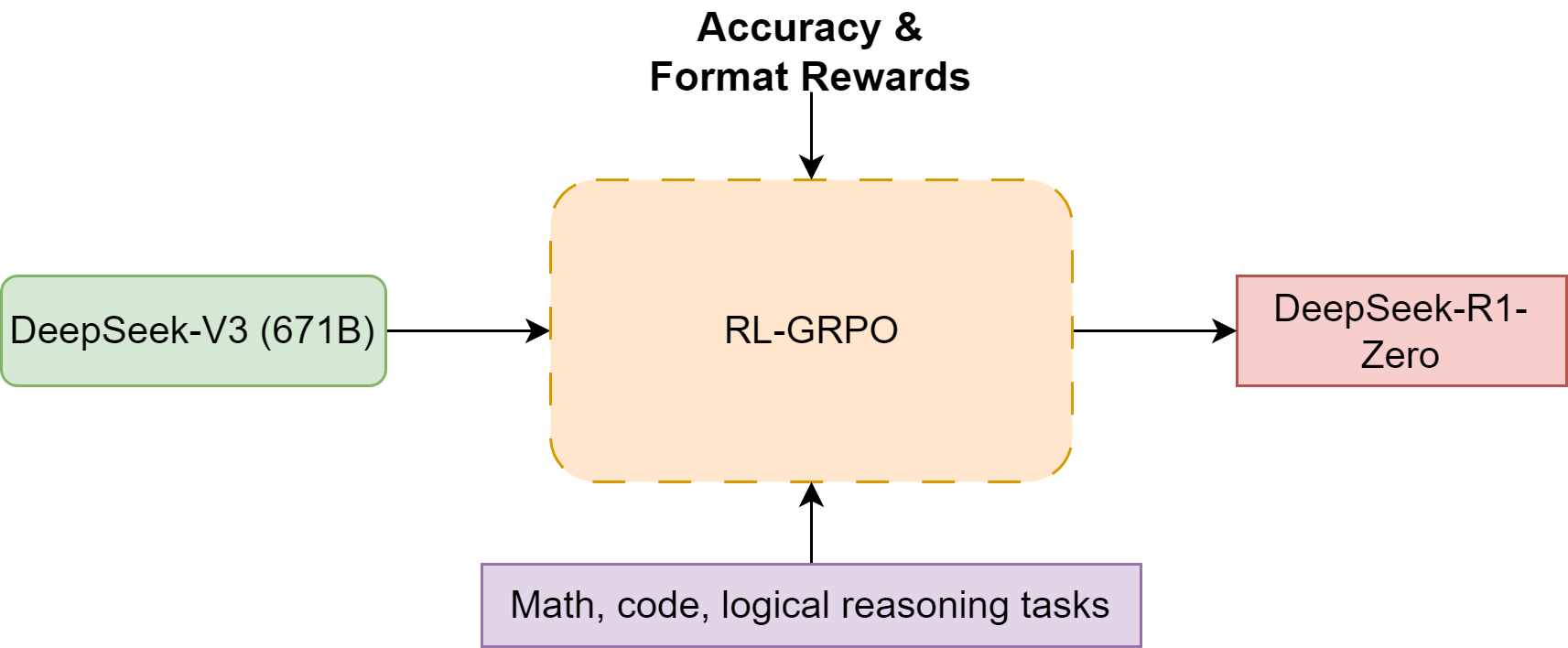
Fig. 18.3 The training workflow for DeepSeek-R1-Zero, which is based on pure reinforcement learning. Reward signals are based on Accuracy reward and format reward.#
Remark 18.1 (Advantages Pure RL)
Pure-RL is slower upfront (trial and error takes time) — but iteliminates the costly, time-intensive labeling bottleneck. Further, the human labeling CoT data is not necessarily the optimal thought process to solve any problems. Using pure RL could have following profound impact in the long run:
Without the data labeling bottleneck, it’ll be faster, scalable, and way more efficient for building reasoning models.
Let’s the model’s self-evolution process to explore better ways to solve problems, instead of relying on human priors. This is necessary for developing superintelligence.
As the training proceeds, the model started to develop sophisticated reasoning behaviors, such as reflection, where the model revisits and reevaluates its previous steps and then the model explores of alternative approaches to problem-solving.
Such self-evolution of reasoning behavior is not a result of explicit programm but instead incentivized from the model’s interaction with the reinforcement learning environment (i.e., the reward signal).
Remark 18.2 (Reward modeling for reasoning task)
Reward modeling for reasoning task is much more straightforward than typical human preference learning tasks, which requires non-trivial efforts to build reward model to approximate complicated human preference.
The reasoning tasks usually have groundtruth - correct answer or not; as a comparison, human preference is usually hard to quantify.
As shown in Fig. 18.4, DeepSeek-R1-Zero learns to allocate more thinking time in solving problems
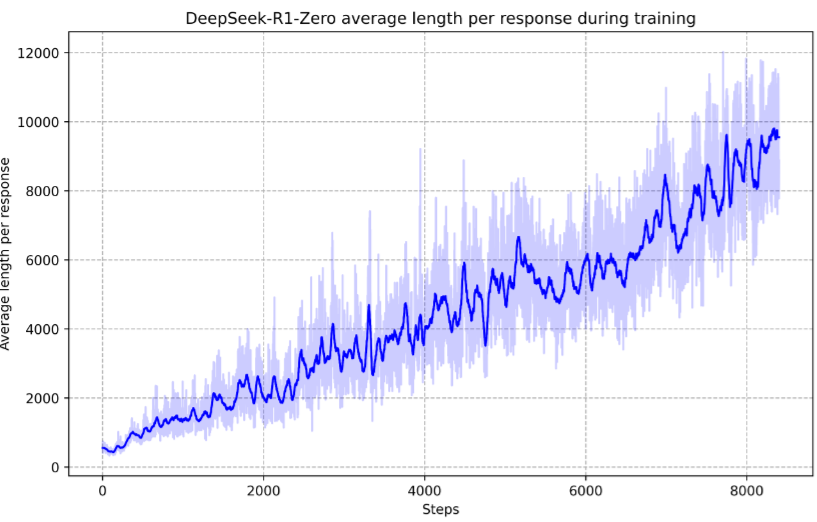
Fig. 18.4 The average response length of DeepSeek-R1-Zero on the training set during the RL process. DeepSeek-R1-Zero naturally learns to solve reasoning tasks with more thinking time. Image from [GYZ+25].#
Model |
AIME 2024 |
MATH-500 |
GPQA |
LiveCode |
CodeForces |
|
|---|---|---|---|---|---|---|
pass@1 |
cons@64 |
pass@1 |
pass@1 |
pating |
||
OpenAI-o1-mini |
63.6 |
80.0 |
90.0 |
60.0 |
53.8 |
1820 |
OpenAI-o1-0912 |
74.4 |
83.3 |
94.8 |
77.3 |
63.4 |
1843 |
DeepSeek-R1-Zero |
71.0 |
86.7 |
95.9 |
73.3 |
50.0 |
1444 |
DeepSeek-R1 |
71.0 |
79.8 |
97.3 |
71.5 |
65.9 |
2029 |
There are also some observed drawbacks from training model - the output has issues like poor readability and language mixing. However, this is expected:
The reward signal does not enforce readability and language mixing.
Enforcing readability and language mixing could interfere with the development of reasoning ability during training process.
18.2.2. DeepSeek-R1#
On top of encourging results from DeepSeek-R1-Zero, DeepSeek-R1 has the objectives of
Further enhancing reasoning performance and accelerate convergence
Improving user-friendliness by generating human readable, clear anc coherent chain of throught
Improving the model’s general ability beyond reasoning tasks.
DeepSeek-R1 main technical approaches improve over Zero by using high-quality cold start data and a multi-stage training pipeline.
The cold start data consists of a small amount (thousands) of long and high-quality (structred, human friendly) CoT data to fine-tune the model as the initial RL actor.
The multi-stage training pipeline is shown in Fig. 18.5, which includes
A supervised fine-tuning stage on cold-start data to get to DeepSeek-R0.25
A subsequent reasoning-oriented RL to get to DeepSeek-R0.5
Additional SFT and RL process on a combined data consisting of
New CoT SFT data collected from DeepSeek-R0.5 via rejection sampling
Existing supervised training data from DeepSeek V3 to enhancing non-reasoning tasks
In the final RL for all scenarios, reward signals are coming from
Reasoning tasks rewards adopt the rule-based reward in DeepSeek-R1-Zero.
Non-reasoning tasks rewards focus on aligning with human preferences, like helpfulness, harmless, and safety.
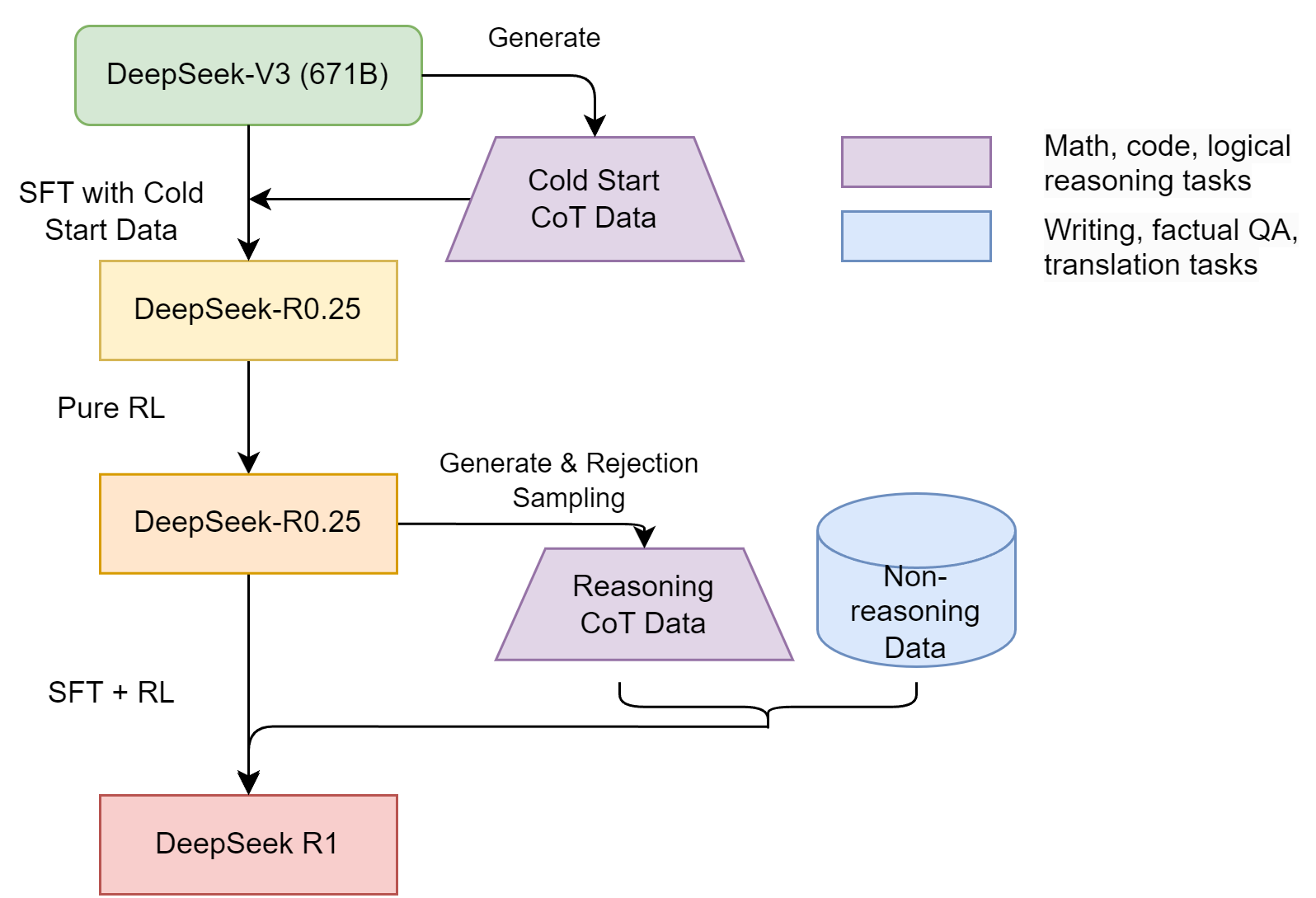
Fig. 18.5 Summary of DeepSeek-R1 multi-stage training, starting from DeepSeek-V3.#
The motivation and technical details on each training stage is summarized as follows
Stage |
Resulted Model |
Motivation & Technical Details |
|---|---|---|
SFT on cold start CoT data |
DeepSeek-R0.25 |
Prevent early instability in RL training; Incorporate human reasoning priors; Improve output readability |
Pure RL |
DeepSeek-R0.5 |
Enhance reasoning ability; Add additional language consistency reward |
Large scale SFT + RL |
DeepSeek-R1 |
Enhance reasoning and general capability; Use ~600k reasoning + ~200k general training samples; Use RL to enhance helpfulness and harmless |
As shown in Fig. 18.6, DeepSeek-R1 achieves comparable performance to OpenAI-o1-1217 on reasoning tasks.
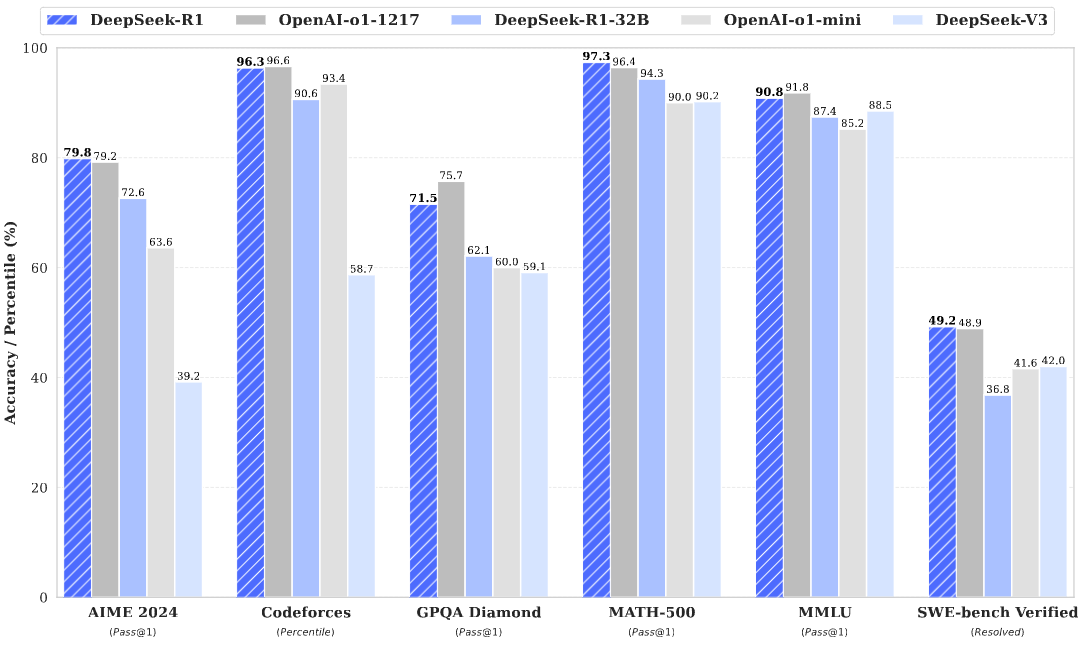
Fig. 18.6 Benchmark performanc of DeepSeek-R1 in reasoning oriented tasks. Image from [GYZ+25].#
18.2.3. DeepSeek-R1-Distillation#
DeepSeek team explored a straightforward distillation approach:
Using the reasoning data generated by DeepSeek-R1
Only SFT is used and does not include an RL stage,
As shown in Table 5, simply distilling DeepSeek-R1’s outputs enables the efficient DeepSeekR1-7B (i.e., DeepSeek-R1-Distill-Qwen-7B, abbreviated similarly below) to outperform nonreasoning models like GPT-4o-0513 across the board. DeepSeek-R1-14B surpasses QwQ-32BPreview on all evaluation metrics,
DeepSeek team also conducted examperiment to answer the question if one can directly apply large-scale RL training to a student model to achieve performance comparable with distillation method?
The results and implications from the following table:
Distilling more powerful models into smaller ones gives much better results than its counterparts trained by large-scale RL, despite the latter requires enormous computational power.
Large-scale RL still need efficiency improvement on computation and samples to achieve on-par results with distillation.
Model |
AIME 2024 |
MATH-500 |
GPQA Diamond |
LiveCodeBench |
|
|---|---|---|---|---|---|
pass@1 |
cons@64 |
pass@1 |
pass@1 |
pass@1 |
|
QwQ-32B-Preview |
50.0 |
60.0 |
90.6 |
54.5 |
41.9 |
DeepSeek-R1-Zero-Qwen-32B |
47.0 |
60.0 |
91.6 |
55.0 |
40.2 |
DeepSeek-R1-Distill-Qwen-32B |
\(\mathbf{7 2 . 6}\) |
\(\mathbf{8 3 . 3}\) |
\(\mathbf{9 4 . 3}\) |
\(\mathbf{6 2 . 1}\) |
\(\mathbf{5 7 . 2}\) |
18.3. Bibliography#
18.3.1. Software#
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, and others. Deepseek-r1: incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948, 2025.
Daya Guo, Qihao Zhu, Dejian Yang, Zhenda Xie, Kai Dong, Wentao Zhang, Guanting Chen, Xiao Bi, Yu Wu, YK Li, and others. Deepseek-coder: when the large language model meets programming–the rise of code intelligence. arXiv preprint arXiv:2401.14196, 2024.
Swaroop Mishra, Matthew Finlayson, Pan Lu, Leonard Tang, Sean Welleck, Chitta Baral, Tanmay Rajpurohit, Oyvind Tafjord, Ashish Sabharwal, Peter Clark, and others. Lila: a unified benchmark for mathematical reasoning. arXiv preprint arXiv:2210.17517, 2022.
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Y Wu, and others. Deepseekmath: pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300, 2024.
Peiyi Wang, Lei Li, Zhihong Shao, RX Xu, Damai Dai, Yifei Li, Deli Chen, Y Wu, and Zhifang Sui. Math-shepherd: a label-free step-by-step verifier for llms in mathematical reasoning. arXiv preprint arXiv:2312.08935, 2023.
Xiang Yue, Xingwei Qu, Ge Zhang, Yao Fu, Wenhao Huang, Huan Sun, Yu Su, and Wenhu Chen. Mammoth: building math generalist models through hybrid instruction tuning. arXiv preprint arXiv:2309.05653, 2023.