8. GPT Series#
8.1. GPT-1#
8.1.1. Introduction#
GPT-1 [RNSS18] and its successors (GPT-2 and GPT-3) are a series Transformer-based model architectures aim to offer generic task-agnostic model architecture and learning schemes to diverse natural language processing (NLP) tasks, such as textual entailment, question answering, semantic similarity assessment.
At that time, specific NLP tasks requires the collection of a massive amount of task-specific labeled data as well as the design of task-specific architectures that learns best from it. Given the broad range of NLP tasks, this paradigm does not scale well and model learning cannot be shared across different tasks.
One of the major contributions of the GPT-1 study is the introduction of a two-stage paradigm to NLP tasks, including an unsupervised pretraining stage and a supervised fine-tuning stage. They demonstrates that a pre-trained model with a small scale fine-tuning can achieve satisfactory results over a range of diverse tasks, not just for a single task.
GPT-1 model consists of multiple transformer decoder layers [Transformers Anatomy]. The pretraining task is auto-regression language modeling, that it, predicting the next word given the preceding word sequence. In the Transformer architecture, the activation in the final transformer block is fed into a Softmax function that produces the word probability distributions over an entire vocabulary of words to predict the next word.
In the stage unsupervised pretraining from unlabeled data, the goal is to learn a universal language representation that can be easily adapted to a wide range of tasks. Following the pretraining, the model can be easily fine-tuned to a downstream task by a relatively small amount of task-specific data to achieve effective transfer. This two-stage scheme had a profound impact on the subsequent deep model learning and drew significant interest to pretrained large language models.
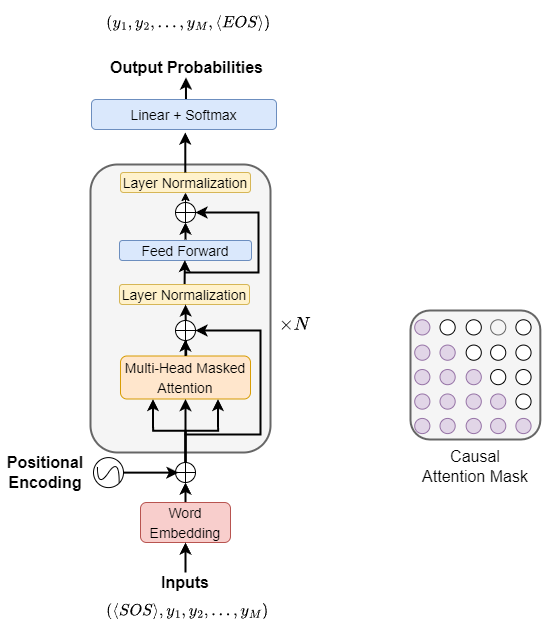
Fig. 8.1 GPT uses the decoder component in the Transformer for language modeling.#
8.1.2. Pretraining#
The pretraining task of GPT-1 is auto-regressive language modeling, which predict the next words given preceding word sequence. Given an input sequence \(\mathbf{x} = (x_1,...,x_T)\), auto-regressive language modeling maximizes the log likelihood given by
where \(p\left(x_{t} \mid \mathbf{x}_{t-k-1:t-1}\right)\) is the predicted probability distribution for token \(x_t\) given preceding token sequence \(\mathbf{x}_{t-k-1:t-1}\) with a context window size \(k\) (\(k\) can range from hundreds to tens of thousands, depending on the model configuration).
The input tokens are first converted to input embeddings by summing up token embedding and position embedding. The input embedding \(H_0\in \mathbb{R}^{T\times d_{model}}\) is then fed into \(L\) Transformer layers to obtain contextualized embedding representation \(H_L\). The contextualized embedding is then passed through a linear layer and a Softmax layer to produce an output distribution over target tokens:
where \(W_{e}\) is the token embedding matrix, and \(W_{p}\) is the position embedding matrix.
GPT-1 uses the BooksCorpus dataset for pretraining. BooksCorpus is a large collection of free novel books (11,038 books), containing around 74M sentences and 1G words in 16 different sub-genres (e.g., Romance, Historical, Adventure, etc.). Pretrained GPT-1 can achieve a very low token level perplexity of 18.4 on this corpus.
8.1.3. GPT-1 Fine Tuning#
The pretrained GPT model can be adopted for different downstream tasks by modifying the inputs format or adding minimal component accordingly. As summarized in Fig. 8.2,
For sequence tasks such as text classification, the input is passed through the network as-is, and an added the output linear layer takes the last activation to make a classification decision.
For sentence-pair tasks such as textual entailment, the input that is made up of two sequences is marked with a delimiter, which helps the pre-trained model to know which part is premise or hypothesis in the case of textual entailment. Finally, the output linear layer takes the last activation to make a classification decision.
For sentence vector similarity tasks, we use the model to encode the two differently-ordered sentence pairs separately into two sequence representations, which are added element-wise before being fed into the linear output layer.
For tasks like Question Answering and Commonsense Reasoning, in which we are given a context document \(z\), a question \(q\), and a set of possible answers \(\left\{a_{k}\right\}\), we can concatenate the document context and question with each possible answer. Each of these sequences are processed independently with our model and then normalized via a Softmax layer to produce an output distribution over possible answers.
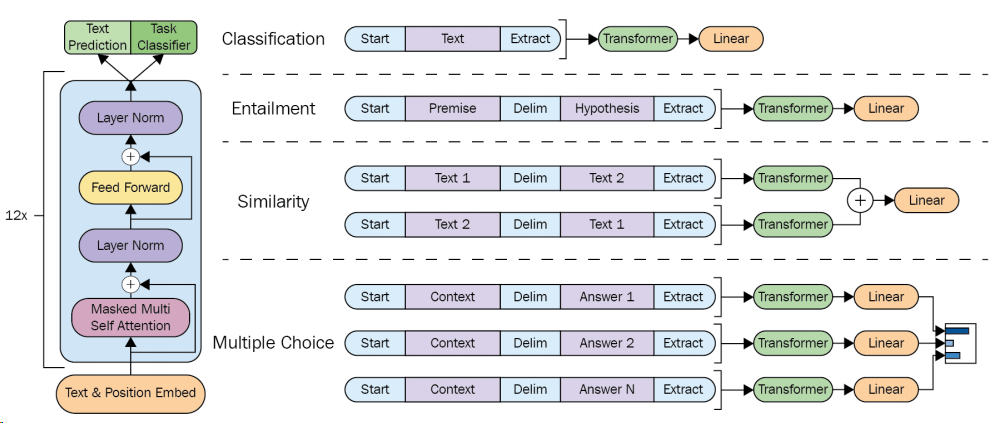
Fig. 8.2 (left) Transformer architecture and training objectives used in this work. (right) Input transformations for fine-tuning on different tasks. We convert all structured inputs into token sequences to be processed by our pre-trained model, followed by a linear+softmax layer. Image from [RNSS18].#
The fine-tuning process involves continuing the model training over a labeled dataset \(\mathcal{C}\). Take text classification task as an example. Suppose that each labeled example consists of a sequence of input tokens, \(x^{1}, \ldots, x^{m}\) along with a label \(y\). The input sequence is first encoded by the pre-trained model to an embedding vector \(h_{l}^{m}\) at the position of the last input token. \(h_{l}^{m}\) is then fed into an linear layer with Softmax to obtain distribution over class labels. The training loss can simply be the binary cross entropy (BCE) loss. It is also found that including language modeling as an auxiliary task during fine-tuning can improve generalization of the fine-tuned model and speed up convergence.
8.2. GPT-2#
GPT-2 [RWC+19], a successor to the original GPT-1, is a larger model trained on much more training data, called WebText, than the original one. It achieved state-of-the-art results on seven out of the eight tasks in a zero-shot setting in which there is no fine-tuning applied but had limited success in some tasks. The key contribution of GPT-2 is not about further refining the two-stage pretraining-fine-tuning paradigm in GPT-1, but about investigating the capability of zero-shot learning with extensively pretrained language model alone. In other words, it aims to answer whether language modeling is a universal task that can help the model to gain universal knowledge that can accomplish other language tasks without subsequent supervised learning.
The intuition is that a model can be very skilled in the sense that it can learn much of the information about a language during the pre-training phase, there will be no need to learn extra information through fine-tuning phase. Take machine translation in the following box as an example, which contains examples of naturally occurring demonstrations of English to French and French to English translation found throughout the WebText training set. By learning to predict future words in the language modeling task, we expect the model to automatically acquire the ability to translate when we can provide the right prompt (e.g., translate from English to French) to the model.
Example 8.1 (Translation pairs can appear naturally in pretraining text corpus)
I’m not the cleverest man in the world, but like they say in French: Je ne suis pas un imbecile [I’m not a fool].
In a now-deleted post from Aug. 16, Soheil Eid, Tory candidate in the riding of Joliette, wrote in French: Mentez mentez, il en restera toujours quelque chose, which translates as, Lie lie and something will always remain.
I hate the word perfume, Burr says. It’s somewhat better in French: parfum.
If listened carefully at 29:55, a conversation can be heard between two guys in French: Comment on fait pour aller de l’autre coté? -Quel autre coté?, which means How do you get to the other side? - What side?.
If this sounds like a bit of a stretch, consider this question in French: As-tu aller au cinéma?, or Did you go to the movies?, which literally translates as Have-you to go to movies/theater?
Brevet Sans Garantie Du Gouvernement, translated to English: Patented without government warranty.
To probe the learned knowledge in the pretraining stage, we specify the task itself through language. That is, a translation task can be specified via translate to french: English text. If corresponding translated French text is produced, it suggests that the pretrained model has acquired the machine translation ability. Likewise, a reading comprehension task can be specified as answer the question: document.
One critical difference between GPT-2 and traditional NLP models that is the task in GPT-2 is formulated within the input, and the model is expected to understand the nature of downstream tasks and provide answers accordingly, while in traditional NLP models we engineer task-specific special symbols and components such that we convert the model’s output to what we need (e.g., a probability). In GPT-2, learning to perform a single task can be expressed in a probabilistic framework as estimating a conditional distribution \(p\) (output|input). Since a general system should be able to perform many different tasks, even for the same input, it should condition not only on the input but also on the task to be performed. That is, it should model \(p\) (output|input, task). Here we can view that input and task specification are provided via language itself rather than by changing part of the model parameters or architectures. This is the key to unlock the task-agnostic language understanding ability for large-scaled pretrained language models.
GPT-2 uses the same Transformer decoder architecture like GPT-1, except that the model size is has been expanded by more than 10 times from GPT-1. The training corpus used by GPT-1is the BookCorpus dataset, while the training corpus used by GPT-2 is crawled from more than 8 million web pages monolingual data, the amount of data is more than 10 times that of the GPT-1.
8.3. GPT-3#
8.3.1. Introduction#
GPT-3 model [BMR+20] has 175 billion parameters, which is 100 times bigger than GPT-2. The architecture of GPT-2 and GPT-3 is similar, with the main differences usually being in the model size and the dataset quantity/quality. As a comparison, GPT-3 has 96 decoder layers with 96 multi-heads attentions and \(d_model\) of 12,288. In comparison, GPT-1 only has 12 layers, 12 heads, and \(d_model\) given by 768. The training data is further expanded from what is used in GPT-2.
Dataset |
Quantity (tokens) |
|---|---|
Common Crawl (filtered) |
410 billion |
WebText2 |
19 billion |
Books1 |
12 billion |
Books2 |
55 billion |
Wikipedia |
3 billion |
The major motivation of GPT-3 is to examine the few-shot learning ability for pretrained language model. This is inspired by the fact that humans can generally perform a new language task from only a few examples or from simple instructions - something which current NLP systems still largely struggle to do. By training on the massive amount of data using a model with large number of parameters, GPT-3 achieved better results on many downstream tasks in zero-shot, one-shot, and few-shot \((K=32)\) settings without any gradient-based fine-tuning.
What is most special about GPT-3 is the ability to perform in-context few-shot learning without any model parameter updates via gradient descent [Fig. 8.3]. In a typical few-shot learning setting, the model is given a natura language description of the task plus a few demonstration examples (e.g., input and output pairs) of the task at inference time and the model is asked to generate an output given a new input. Here the input is called context and the output is called a completion. Take English sentence to French translation as an example, \(K\) examples of context and completion are presented with one final example of context, and the model is expected to provide the completion. Typically, \(K\) is in the range of 10 and 100. Clearly, few-shot learning is close to how human intelligence works and bring great metrics in reducing task-specific data.
In the extreme end of few shot learning, one-shot learning is the case in which only one demonstration is presented. Further, zero-shot is the case where no demonstrations are given except for a natural language instruction describing the task. Zero-shot setting offers the ultimate test of the model’s learning capacity, but it can also be unfairly hard due to ambiguity.
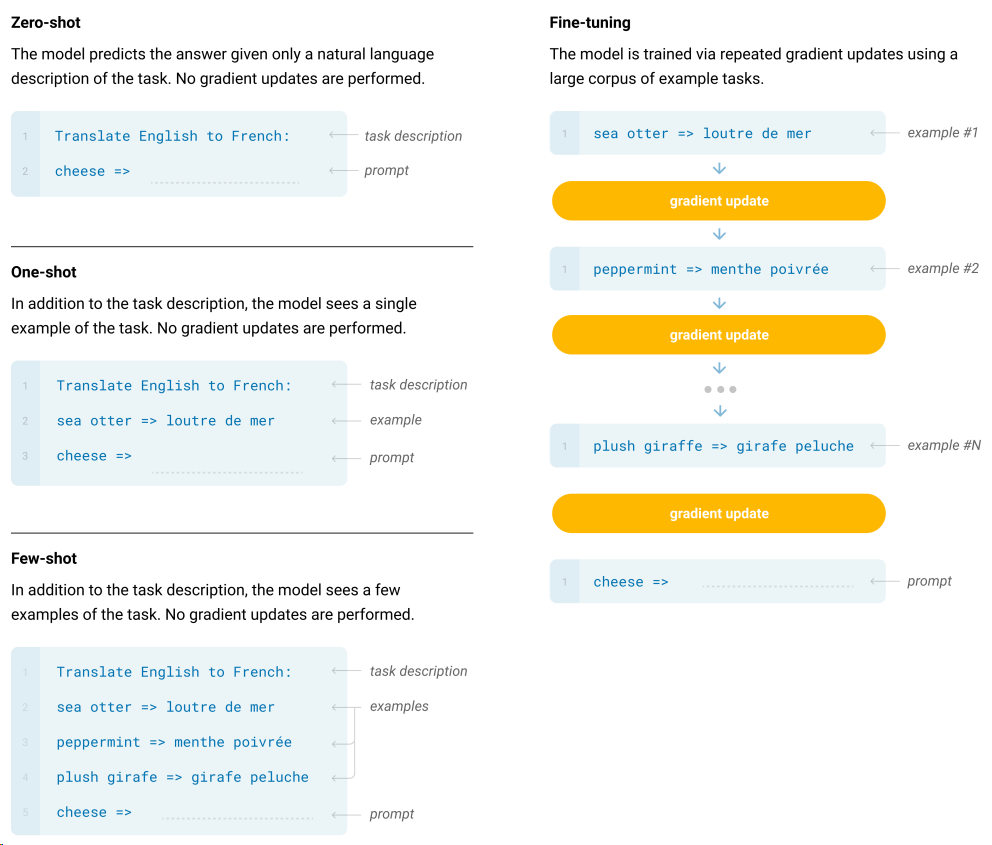
Fig. 8.3 Zero-shot, one-shot and few-shot, contrasted with traditional fine-tuning. Traditional fine-tuning requires gradient computation via backpropgation and update the model weight, whereas zero-, one-, and few-shot, only require the model to perform forward passes at test time.#
8.3.2. Performance Overview#
In the following, we summarize the probing results of GPT-3 in a broad range of domains.
8.3.2.1. Language modeling#
We first look at the language modeling benchmark on Penn Tree Bank, which is a fundamental measure on the model’s capability on understanding and using natural language. GPT-3 is a clear leader in Language Modelling on with a perplexity of 20.5.
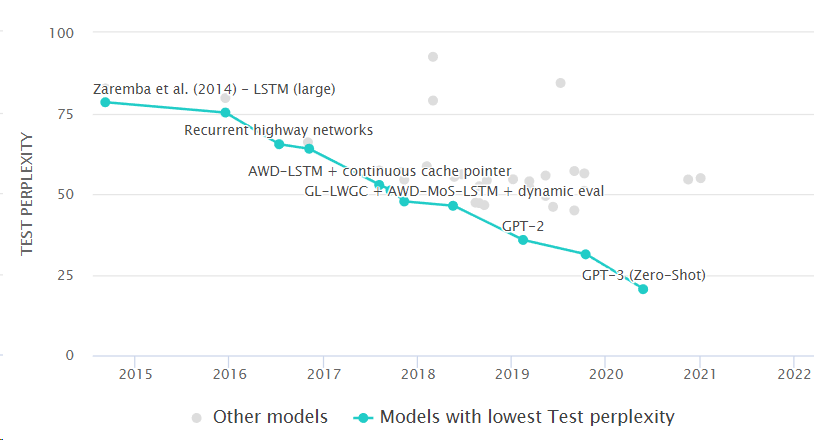
Fig. 8.4 Language modeling benchmark task on Penn Tree Bank. Image from https://paperswithcode.com/sota/language-modelling-on-penn-treebank-word.#
8.3.2.2. News article generation#
Like language modeling, the most natural ability for GPT3 is to generate smooth and nature texts.
Performance is evaluated by how well humans can detect whether generated text is from a model model generated text. Regarding the test, 25 article titles and subtitles from the website are arbitrarily selected, with a mean length of 215 words. Four language models ranging in size from 125M to 175B (GPT-3) are used to generated completions from these titles and subtitles.
Following shows the performance across different model sizes. As the model size increases, the generated texts are more realistic, natural, and coherent, therefore more difficult for humans to detect.
Mean accuracy |
95% Confidence Interval (low, hi) |
|
|---|---|---|
Control (deliberately bad model) |
86% |
83%-90% |
GPT-3 Small |
76% |
72%-80% |
GPT-3 2.7B |
62% |
58%-65% |
GPT-3 6.7B |
60% |
56%-63% |
GPT-3 13B |
55% |
52%-58% |
GPT-3 175B |
52% |
49%-54% |
8.3.2.3. Machine Translation#
GPT-3’s training data consists of primarily English (93% by word count), with an additional 7% of text in other languages. We expect GPT-3 can learns from a blend of training data that mixes many languages together in a natural way, therefor enabling GPT-3 to perform machine translation in zero-shot and few-shot settings.
The following shows the performance comparison among supervised SOTA neural machine translation models, unsupervised multi-lingual pretrained language models, and GPT-3. Supervised models are the clear winners in this domain. However, GPT-3 demonstrates its decent performance when performing translation back to English, probably because GPT-3 is a strong English language model.
The performance GPT-3 also has a noticeable skew depending on language direction. Specifically, GPT-3 significantly outperforms prior unsupervised models when translating into English but under-performs when translating in the other direction.
In general, across all three language models tested, there is a smooth upward trend with model capacity. While in the zero-shot setting, GPT-3 underperforms recent unsupervised model, offering a few demonstrations to GPT-3 can quickly boost the BLEU scores.
Setting |
En → Fr |
Fr → En |
En → De |
De → En |
En → Ro |
Ro → En |
|---|---|---|---|---|---|---|
SOTA (Supervised) |
45.6 |
35.0 |
41.2 |
40.2 |
38.5 |
39.9^e^ |
XLM |
33.4 |
33.3 |
26.4 |
34.3 |
33.3 |
31.8 |
MASS |
37.5 |
34.9 |
28.3 |
35.2 |
35.2 |
33.1 |
mBART |
- |
- |
29.8 |
34.0 |
35.0 |
30.5 |
GPT-3 Zero-Shot |
25.2 |
21.2 |
24.6 |
27.2 |
14.1 |
19.9 |
GPT-3 One-Shot |
28.3 |
33.7 |
26.2 |
30.4 |
20.6 |
38.6 |
GPT-3 Few-Shot |
32.6 |
39.2 |
29.7 |
40.6 |
21.0 |
39.5 |
8.3.2.4. SuperGLUE#
SuperGLUE is a collection of benchmark tests to probe the natural language understanding capacity of a model.
The key take aways from the following SuperGLUE benchmark are:
Scaling: The performance of GPT-3 improves as the model size increases, for both zero shot and few shots. At its largest size (175B), few-shot GPT-3 outperforms fine-tuned BERT++ and BERT Large models, approaching but not quite reaching the performance of fine-tuned SOTA (State of the Art) models.
Few-shot in-context learning: GPT-3 performs well in few-shot settings (K=32), outperforming one-shot and zero-shot learning for most model sizes. In general, more examples provided, the better the performance, plateauing around 16-32 examples.
Human benchmark: While GPT-3’s performance is impressive, it still falls short of human-level performance on SuperGLUE
Slow improvement at large sizes: steep improvements in performance with initial increases in model size or number of examples, followed by a more gradual improvement as these numbers get larger.
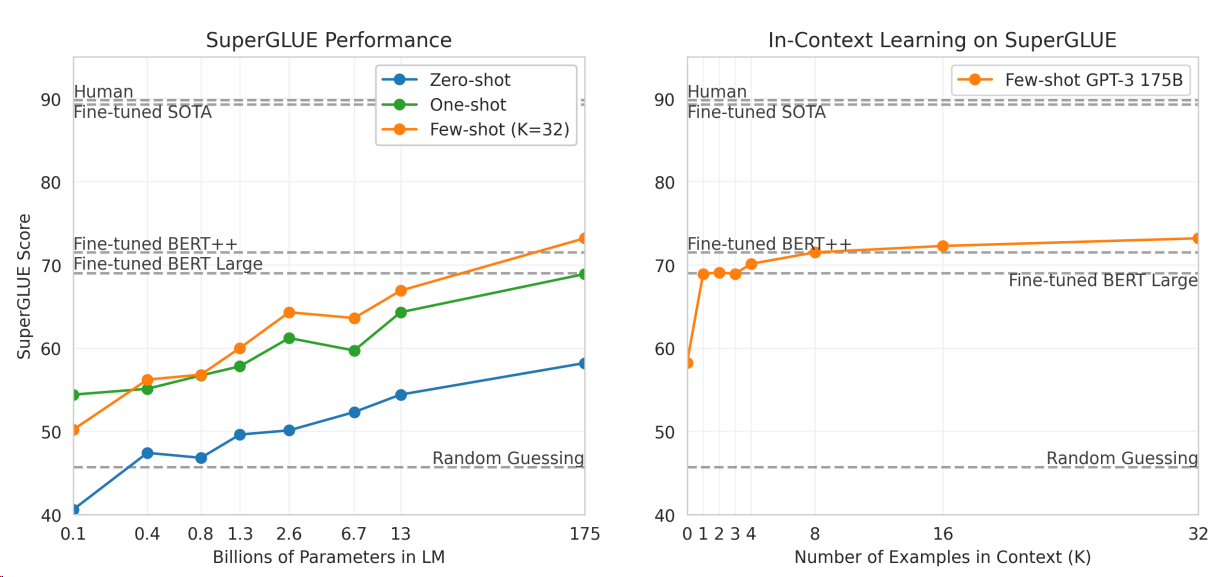
Fig. 8.5 Performance on SuperGLUE increases with model size and number of examples in context.#
8.3.2.5. Closed-book question answering#
Closed-book question answering is used to examine GPT-3’s ability to answer questions about broad factual knowledge. Contrast with open-book question answering, in which
An information retrieval module is first used to retrieve question-relevant paragraphs
The model is perform reading comprehension on the retrieved text to extract or produce the answers.
The GPT-3 model was tested on Natural Questions, WebQuestions, and TriviaQA datasets, and the results are the following. The performance of GPT-3 improves as the model size increases, for both zero shot and few shots. At its largest size (175B), few-shot GPT-3 outperforms the fine-tuned SOTA.

Fig. 8.6 On TriviaQA GPT3’s performance grows smoothly with model size, suggesting that language models continue to absorb knowledge as their capacity increases. One-shot and few-shot performance make significant gains over zero-shot behavior, matching and exceeding the performance of the SOTA fine-tuned open-domain model#
8.3.2.6. Common Sense Reasoning#
GPT-3 was tested on three datasets which attempt to capture physical or scientific reasoning.
As for physical or scientific reasoning, GPT-3 is not outperforming fine-tuned SOTA methods; however, there is a clear trend that more examples in the prompt will help.
Setting |
PIQA |
ARC (Easy) |
ARC (Challenge) |
OpenBookQA |
|---|---|---|---|---|
Fine-tuned SOTA |
79.4 |
92.0 |
78.5 |
87.2 |
GPT-3 Zero-Shot |
80.5 |
68.8 |
51.4 |
57.6 |
GPT-3 One-Shot |
80.5 |
71.2 |
53.2 |
58.8 |
GPT-3 Few-Shot |
82.8 |
70.1 |
51.5 |
65.4 |
8.3.2.7. Arithmetic tasks#
Arithematic tasks fall into ene category of reasoning tasks and they are intrinsically challenging to NLP model up to today. As shown by the following the results, while GPT-3 does not excel at arithmetic tasks, we observe a rapid increase of skill starting from 7B model size. This is indicating that arithmetic reasoning is one emergent ability for LLMs.
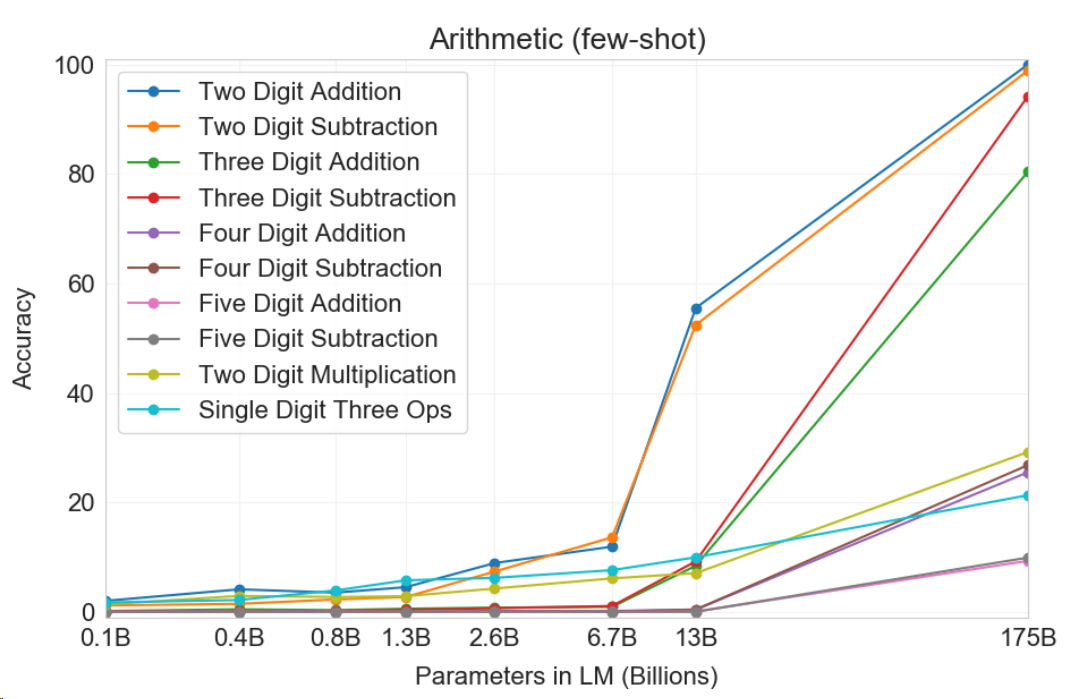
Fig. 8.7 Results on all 10 arithmetic tasks in the few-shot settings for models of different sizes. There is a significant jump from the second largest model (GPT-3 13B) to the largest model (GPT-3 175)#
8.4. Bibliography#
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, and et al. Language models are few-shot learners. Advances in Neural Information Processing Systems, 33:1877–1901, 2020.
Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. Improving language understanding by generative pre-training. URL https://s3-us-west-2. amazonaws. com/openai-assets/researchcovers/languageunsupervised/language understanding paper. pdf, 2018.
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners. OpenAI Blog, 1(8):9, 2019.