7. Seq2Seq: T5 and BART#
7.1. T5#
7.1.1. Overview#
Pretrained language models and transfer learning enable a diverse range of NLP tasks to be solved by a generic and unified architecture paradigm consisting of an representation encoder from the pretrained language model plus a task-dependent prediction head. T5 (Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer) [RSR+20] push this limits further. Based on encoder-decoder Transformer model, T5 proposed a unifying framework to solve many tasks by casting them to a text-to-text problem, where input and output, as well as the task description, are a list of text tokens.
The following diagram Fig. 7.1 illustrates how T5 solves four different NLP problems within a unified framework, including machine learning, linguistic acceptability, semantic similarity, and text summarization.
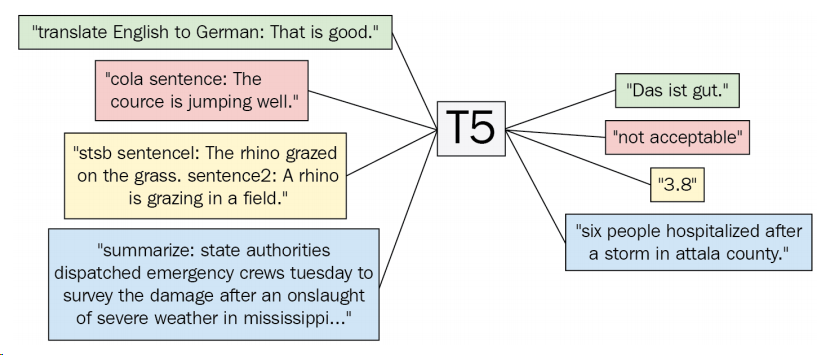
Fig. 7.1 Illustration of the text-to-text universal transfer learning framework for a diverse range of tasks.#
Particularly, the model is fed with text that is made up of a task prefix and the input attached to it. We convert a labeled textual dataset to a format like {Task: ‘….’, ‘targets’ : … ‘ } format, where we insert the purpose in the input as a prefix.
Example 7.1
In order to train a single model on the diverse set of tasks described above, we need a consistent input and output format across all tasks. As recently noted by [RWC+19, MKXS18], it is possible to formulate most NLP tasks in a text-to-text format - that is, a task where the model is fed some text for context or conditioning and is then asked to produce some output text.
To specify which task the model should perform, we add a task-specific (text) prefix to the original input sequence before feeding it to the model. As an example,
To ask the model to translate the sentence “That is good.” from English to German, the model would be fed the sequence “translate English to German: That is good.” and would be trained to output “Das ist gut.”
For text classification tasks, the model simply predicts a single word corresponding to the target label. For example, on the MNLI benchmark the goal is to predict whether a premise implies entailment, contradicts, or neither neutral. With our preprocessing, the input sequence becomes “mnli premise: I hate pigeons. hypothesis: My feelings towards pigeons are filled with animosity.”
For the English-German translation task, the “translate English to German: That is good.” input is going to produce “das is gut.”.
Based on the task-agnostic architecture proposed by T5, solving different NLP tasks becomes how to convert the task into suitable text input output. T5 apply the same model, objective, training procedure, and decoding process for every NLP task.
7.1.2. Pretraining#
T5 has explored a variant of masking strategies for masked language modeling based pretraining. These masking strategies shares some span of texts with different mask tokens and train the model to only predict masked texts and use mask tokens to indicate the position of recovered texts.
Original Text |
Thank you for inviting me to your party last week. |
|---|---|
Input masked text ( \(15 \%\) random masking) |
Thank you \(<\mathrm{X}>\) me to your party \(<\mathrm{Y}>\) week. |
Target text |
\(<\mathrm{X}>\) for inviting \(<\mathrm{Y}>\) last \(<\mathrm{Z}>\) |
Besides using large-scale corpus of masked language pretraining, T5 model also utilizes labeled data from different downstream tasks for multi-task pretraining. The purpose is to obtain an improved task-agnostic representations via multi-task learning, since learning from multiple related tasks can improve the robustness.
7.2. BART#
7.2.1. Overview#
The key contribution of BART (Bidirectional and Auto-Regressive Transformers) [LLG+19] is using Seq2Seq Transformer architecture to combine the advantage of bidirectional auto-encoder scheme (like BERT) and Auto-regressive scheme (like GPT).
With well-design pretraining tasks, BART, when fine tuned, is particularly effective for both text generation and for language comprehension tasks. BART has achieved state-of-the-art performance in generative tasks, such extractive summarization, dialogue, and abstractive QA.
7.2.2. Pre-training#
BART adopts a slightly modified Transformer architecture with a bidirectional encoder over corrupted text and a uni-directional autoregressive decoder to recover the original text.
The most important pre-training task for BART is to predict a masked token and use the entire input to get more complete information to make more accurate predictions, with two steps:
First, add noise and mask to the input and then use the encoder part to encode noisy input text.
Second, use an uni-directional decoder to reconstruct the original text, including recover the order and masked words.
In the masked language model pretraining task in BERT, the prediction of masked words are independent and does not condition on the prediction of other masked words. In BART, masked words are predicted through auto-regression, allowing the prediction of one masked work to condition other preceding masked words. The BART style pretraining therefore tend to produce representations that are amenable to text generation downstream tasks, in which each word depends on the previously generated words.
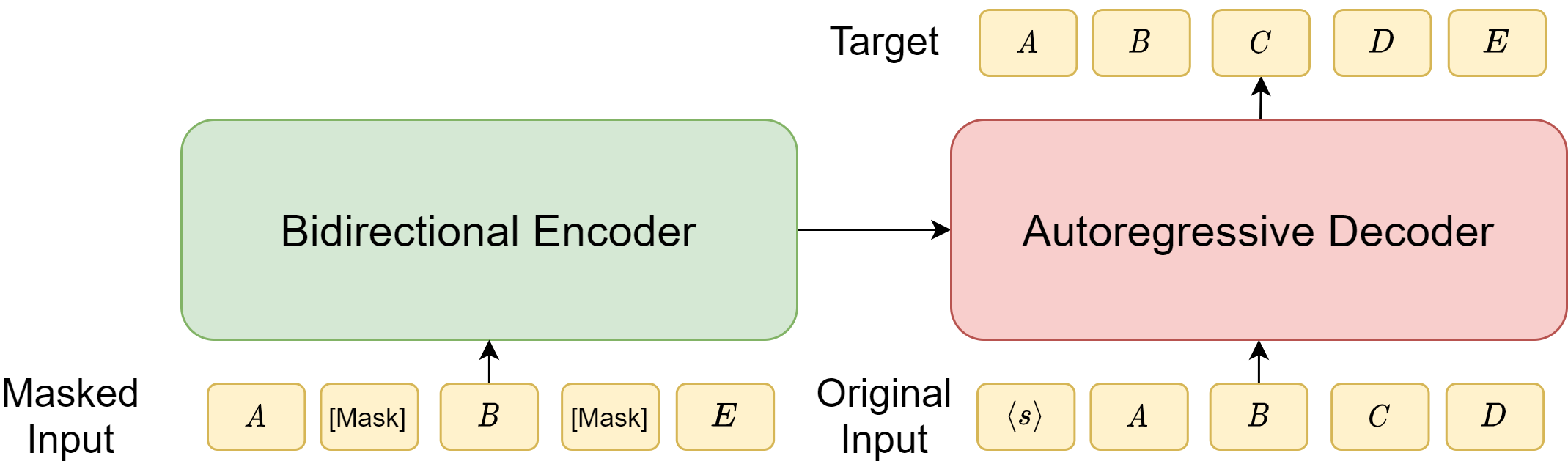
Fig. 7.2 Illustration of BART architecture, which consists of a bidirectional encoder (like BERT) and an auto-regressive decoder (like GPT). The original input is ABCDE, while the masked input has text CD masked out and an additional mask inserted before B. The decoder needs to predict the original input offset by one step using the encoder’s output and the original input.#
BART is pretrained by optimizing a reconstruction loss, which is the cross-entropy between the decoder’s output and the original document. Because of the adoption of the Seq2Seq architecture, BART allows the application of any type of input corruption. When all the information to the encoder is lost, the BART’s decoder part is equivalent to a language model.
We will look at each input corruption scheme and its underlying motivation in detail [Fig. 7.3]:
Technique |
Description |
|---|---|
Token Masking |
Tokens are randomly masked with a [MASK] symbol, same as with the BERT model. The model is pre-trained to predict a token based on its context. |
Token Deletion |
Tokens are randomly removed from the documents. The model is pre-trained to determine tokens at which positions are removed. |
Text Infilling |
A number of text spans with different lengths (including zero length) are sampled, and then they are replaced by a single [MASK] token. The model is pre-trained to decide how many tokens a span corresponds to. |
Sentence Permutation |
The sentences in the input are segmented based on full stops and shuffled in random order. The model is pre-trained to understand the relationship between sentences. |
Document Rotation |
The input is rotated (i.e., is right shifted) so that it begins with a randomly selected token. The model is pre-trained to find the start position of a document. |
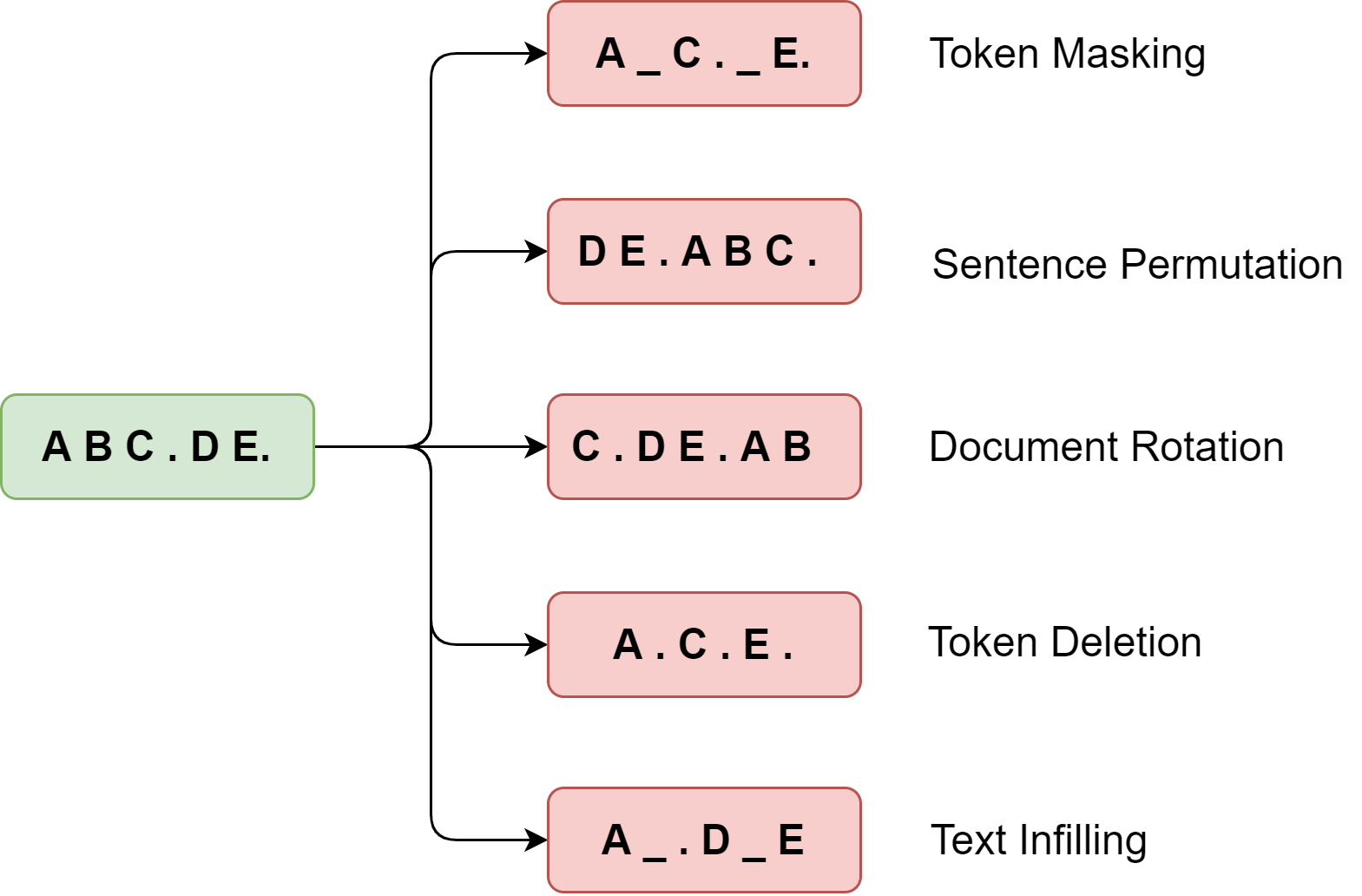
Fig. 7.3 Different input text corruption schemes in BART.#
7.2.3. Pretraining performance analysis#
The followings shows the performance on pretraining objectives. (Table from [LLG+19]).
Model |
SQuAD 1.1 |
MNLI |
ELI5 |
XSum |
ConvAI2 |
CNN/DM |
|---|---|---|---|---|---|---|
F1 |
Acc |
PPL |
PPL |
PPL |
PPL |
|
BERT Base (Devlin et al., 2019) |
88.5 |
\(\mathbf{8 4 . 3}\) |
- |
- |
- |
- |
Language Model |
76.7 |
80.1 |
\(\mathbf{2 1 . 4 0}\) |
7.00 |
11.51 |
6.56 |
BART Base |
||||||
w/ Token Masking |
90.4 |
84.1 |
25.05 |
7.08 |
11.73 |
6.10 |
w/ Token Deletion |
90.4 |
84.1 |
24.61 |
6.90 |
11.46 |
5.87 |
w/ Text Infilling |
\(\mathbf{9 0 . 8}\) |
84.0 |
24.26 |
\(\mathbf{6 . 6 1}\) |
\(\mathbf{1 1 . 0 5}\) |
5.83 |
w/ Document Rotation |
77.2 |
75.3 |
53.69 |
17.14 |
19.87 |
10.59 |
w/ Sentence Shuffling |
85.4 |
81.5 |
41.87 |
10.93 |
16.67 |
7.89 |
w/ Text Infilling + Sentence Shuffling |
\(\mathbf{9 0 . 8}\) |
83.8 |
24.17 |
6.62 |
11.12 |
\(\mathbf{5 . 4 1}\) |
7.2.4. Model Fine Tuning#
The pre-trained BART model has both text representation and generation capabilities, so it is applicable for both language understanding and text generation downstream tasks.
7.2.4.1. Language Understanding Tasks#
Sequence classification For sequence or token classification tasks, the encoder and decoder of BART use the same input, and the state of the hidden layer at the final moment of the decoder is used as the vector representation of the input text. The vector representation is fed into the multi-class linear classifier. Similar to the [CLS] token of the BERT model, the BART model adds an additional special token at the last position of the decoder input, and uses the hidden layer state of this token as the representation of the text.
Token classification. For sequence or token classification tasks, the encoder and decoder of BART use the same input, the top hidden state of the decoder as a representation for each word. The vector representation is fed into the multi-class linear classifier.
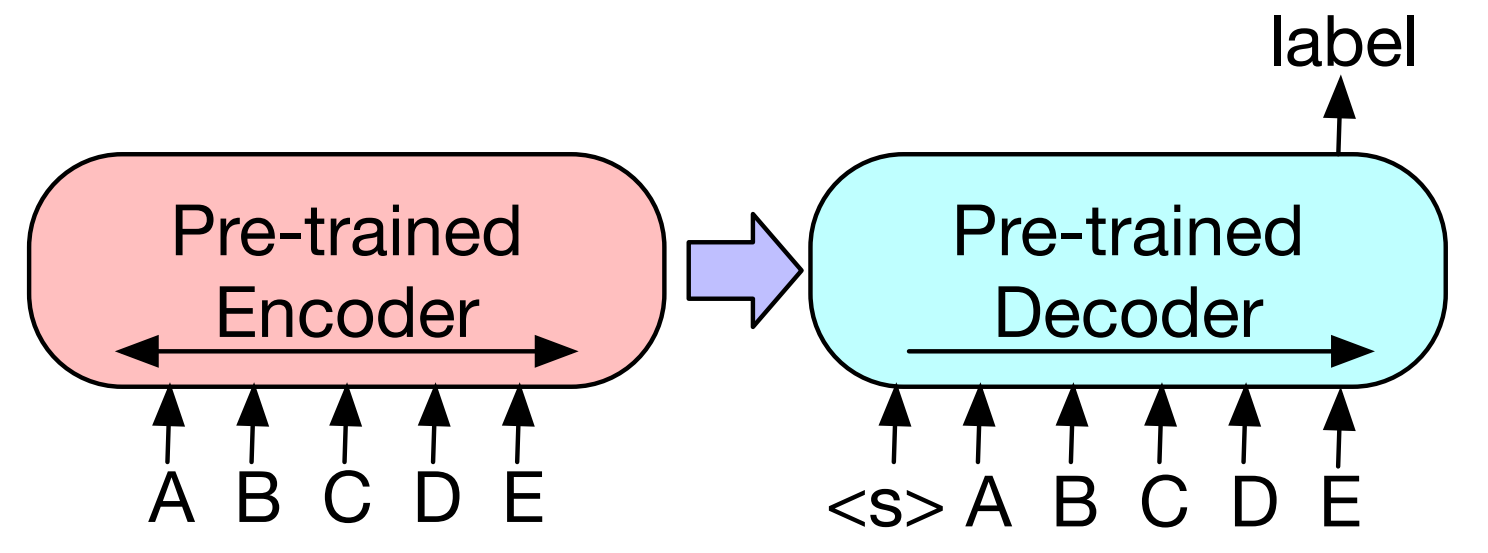
Fig. 7.4 To use BART for classification problems, the same input is fed into the encoder and decoder, and the representation from the final output is used. Image from [LLG+19].#
7.2.4.2. Text Generation Tasks#
Text generation. BART models can be used directly for conditional text generation tasks such as text summarization. Take text summarization as an example, the input of the encoder is the text to be summarized, and the decoder generates the corresponding target text in an auto-regressive manner.
Machine translation. When used for machine translation tasks, the BART model cannot be directly fine-tuned because the source and target languages use different vocabulary sets. Therefore, the researchers propose to replace the input embedding layer of the BART model encoder with a small Transformer encoder, which is used to align the vocabulary in the source language to the input representation space of the target language. During the fine-tuning phase, the parameters of this newly introduced source language encoder are randomly initialized, and most of the other parameters of the BART model are pre-trained.
There are two stages in the fine-tuning phase.
First, only the source language encoder, the BART model position vector, and the self-attention input projection matrix of the first layer of the BART pretrained encoder are trained; The rest of model parameters are fixed.
Second, a small number of iterations are performed on all model parameters.
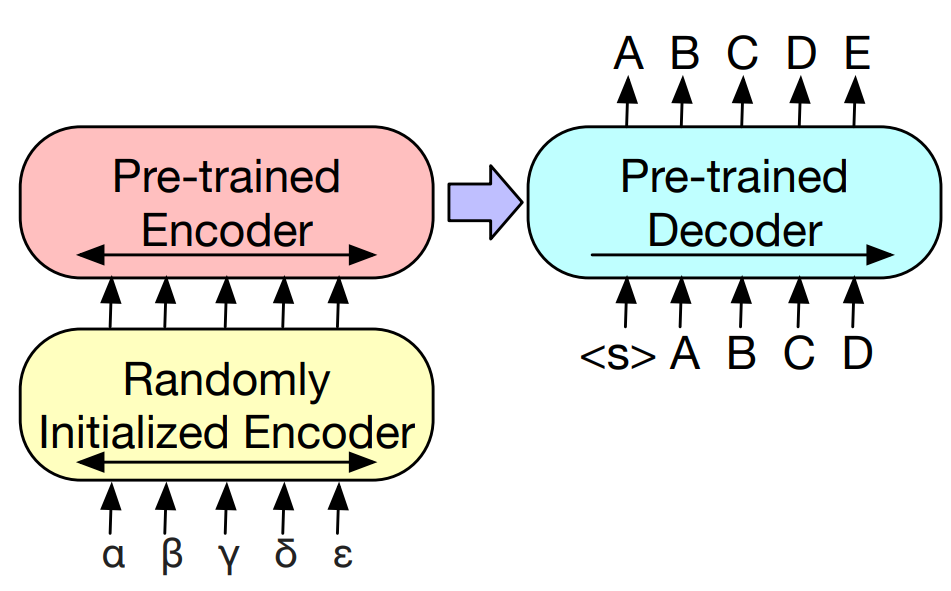
Fig. 7.5 For machine translation, we learn a small additional encoder that replaces the word embeddings in BART. The new encoder can use a disjoint vocabulary. Image from [LLG+19].#
7.3. Bibliography#
Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov, and Luke Zettlemoyer. BART: denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. ArXiv:1910.13461, 2019.
Bryan McCann, Nitish Shirish Keskar, Caiming Xiong, and Richard Socher. The natural language decathlon: multitask learning as question answering. arXiv preprint arXiv:1806.08730, 2018.
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners. OpenAI Blog, 1(8):9, 2019.
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of Machine Learning Research, 21(140):1–67, 2020.