24. LLM Text Embedding#
24.1. LLM Embedding Model#
24.1.1. NV-Embed#
NV-Embed from Nvidia [LRX+24] proposed several improvement techniques on LLM-based embedding model, which include:
Model architecture improvement, which introduces a latent attention layer to obtain better pooled embeddings.
Traing process improvement, which introduces a two-stage contrastive instruction-tuning method.
There are two popular methods to obtain the embedding for a sequence of tokens:
Mean pooling of the all hidden vectors of the last layer, which is commonly used in bidirectional embedding models.
Last
token embedding, which is more popular for decoder-only LLM based embedding models.
However, both methods have certain limitations. Mean pooling simply takes the average of token embeddings and may dilute the important information from key phrases, meanwhile the semantics of the last
The latent attention layer aims to improve the mean pooling method. Denote the last layer hidden from decoder as the query \(Q \in \mathbb{R}^{l \times d}\), where \(l\) is the length of sequence, and \(d\) is the hidden dimension. They are sent to attend the latent array \(K=V \in \mathbb{R}^{r \times d}\), which are trainable matrices, used to obtain better representation, where \(r\) is the number of latents in the dictionary. The output of this cross-attention is denoted by \(O \in \mathbb{R}^{l \times d}\),
Intuitively, each token’s represention in \(O\) (which is a \(d\) vector) is a linear combination of the \(r\) row vectors in \(V\)(or \(K\)).
This has the spirit of sparse dictionary learning[MBPS09], which aims to learn a sparse set of atom vectors, such that each representation can be transformed to a linear combination of atom vectors.
An additional 2-layer MLP was added to further transfrom the \(O\) vectors. Finally, a mean pooling after MLP layers to obtain the embedding of whole sequences.
In the paper, authors used latent attention layer with \(r\) of 512 and the number of heads as 8 for multi-head attention.
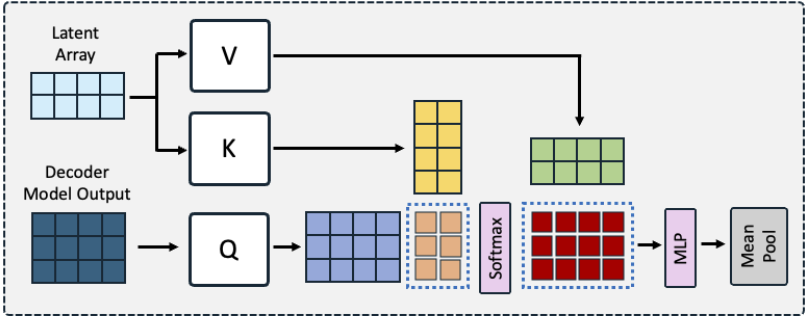
Fig. 24.1 The illustration of proposed architecture design comprising of decoder-only LLM followed by latent attention layer. Latent attention layer functions as a form of cross-attention where the decoder-only LLM output serves as queries (Q) and trainable latent array passes through the keyvalue inputs, followed by MLP. Image from [LRX+24].#
The two-stage instruction tuning method include
First-stage contrastive training with instructions on a variety of retrieval datasets, utilizing in-batch negatives and curated hard-negative examples.
Second stage contrastive instruction-tuning on a combination of retrieval and non-retrieval datasets (e.g., classification ) without applying the trick of in-batch negatives.
The design rationale behind the two-stage finetunings are:
It is found that retrieval task presents greater difficulty compared to the non-retrieval tasks there is one stage training fully dedicated to the retrieval task.
In second stage, as the retrieval and non-retrieval tasks are blended, it is necessary to remove in-batch negatives trick. Since the negative may come from the the class and are not true negatives.
24.1.2. GTE Qwen 7B#
gte-Qwen2-7B-instruct is the latest addition to the gte embedding family. This model has been engineered starting from the Qwen2-7B LLM, drawing on the robust natural language processing capabilities of the Qwen1.5-7B model. Enhanced through our sophisticated embedding training techniques, the model incorporates several key advancements:
Integration of bidirectional attention mechanisms, enriching its contextual understanding. Instruction tuning, applied solely on the query side for streamlined efficiency Comprehensive training across a vast, multilingual text corpus spanning diverse domains and scenarios. This training leverages both weakly supervised and supervised data, ensuring the model’s applicability across numerous languages and a wide array of downstream tasks.
When encoding the query, we need to add the following prompt text in front (it is not needed for document encoding). Prompt: “Instruct: Given a web search query, retrieve relevant passages that answer the query\nQuery: “
24.2. LLM Embedding Adaptation#
24.2.1. E5 Mistral 7B#
The authors in [WYH+23] hypothesize that generative language modeing are two sides of the same coin, with both of them requiring the model to have a deep understanding of the natural language. Given an embedding task definition, a capable LLM could be transformed into an embedding model with ligh-weight fine-tuning, without the need of conducting extensive contrastive pretraining like small models (see General-Purpose Text Embedding).
The synthetic retrieval tasks are grouped into
Asymmetric tasks, which consist of tasks where the query and document are semantically related but are not paraphrases of each other. Typical scenario in commercial search engines is an asymmetric task.
Symmetric tasks, which involve queries and documents that have similar semantic meanings but different surface forms. Monolingual semantic textual similarity (STS) and bitext retrieval are example tasks.

Fig. 24.2 Synthetic data preparation step one: prompting LLM to brainstorm retrieval tasks. Image from [WYH+23].#

Fig. 24.3 Synthetic data preparation step two: prompting LLM to generate positive and negative pairs for a given retrieval task. Image from [WYH+23].#
To enable LLM to generate task-dependent embedding, given a relevant query-document pair \(\left(q^{+}, d^{+}\right)\), we first apply the following instruction template to the original query \(q^{+}\)to generate a new one \(q_{\text {inst }}^{+}\):
Here task_definition is a placeholder for a one-sentence description of the embedding task.
With generated synthetic data and limited labeled data from MS MARCO, one can
First extract text embedding from the hidden state of EOS token appended after query or doc.
Then perform contrastive learning on the positive and negative examples.
The evaluation and comparison with other fine-tuned models on MTEB benchmark give the following key findings:
Overall E5 mistral-7B with full data finetuning gives the strongest performance.
In the “w/ synthetic data only” setting, where no labeled data is used for training, the model’s performance remains quite competitive.
# of datasets |
Class. |
Clust. |
PairClass. |
Rerank |
Retrieval |
STS |
Summary |
Avg |
|---|---|---|---|---|---|---|---|---|
SimCSE bert-sup |
67.3 |
33.4 |
73.7 |
47.5 |
21.8 |
79.1 |
23.3 |
48.7 |
Contriever |
66.7 |
41.1 |
82.5 |
53.1 |
41.9 |
76.5 |
30.4 |
56.0 |
GTE large |
73.3 |
46.8 |
85.0 |
59.1 |
52.2 |
83.4 |
31.7 |
63.1 |
E5 mistral-7b w/ full data |
78.5 |
50.3 |
88.3 |
60.2 |
56.9 |
84.6 |
31.4 |
66.6 |
w/ synthetic data only |
78.2 |
50.5 |
86.0 |
59.0 |
46.9 |
81.2 |
31.9 |
63.1 |
w/ synthetic + msmarco |
78.3 |
49.9 |
87.1 |
59.5 |
52.2 |
81.2 |
32.7 |
64.5 |
Remark 24.1 (Impact of contrastive pre-training)
The authors found that Mistral-7B based models, contrastive pre-training has negligible impact on the model quality. This implies that extensive auto-regressive pre-training enables LLMs to acquire good text representations, and only minimal fine-tuning is required to transform them into effective embedding models.
24.3. LLM Embedding Distillation#
[LDR+24]
24.4. Bibliography#
Chankyu Lee, Rajarshi Roy, Mengyao Xu, Jonathan Raiman, Mohammad Shoeybi, Bryan Catanzaro, and Wei Ping. Nv-embed: improved techniques for training llms as generalist embedding models. arXiv preprint arXiv:2405.17428, 2024.
Jinhyuk Lee, Zhuyun Dai, Xiaoqi Ren, Blair Chen, Daniel Cer, Jeremy R Cole, Kai Hui, Michael Boratko, Rajvi Kapadia, Wen Ding, and others. Gecko: versatile text embeddings distilled from large language models. arXiv preprint arXiv:2403.20327, 2024.
Julien Mairal, Francis Bach, Jean Ponce, and Guillermo Sapiro. Online dictionary learning for sparse coding. In Proceedings of the 26th annual international conference on machine learning, 689–696. ACM, 2009.