27. Advanced RAG (WIP)#
27.1. Corrective RAG (CRAG)#
CRAG aims to address the concerns that low-quality retrieved results can mislead the generator to produce non-factual and hallucinated results.
The Key design is: Given an input query and the retrieved documents from any retriever, a lightweight retrieval evaluator (e.g., <1B) is constructed to estimate the relevance score of retrieved documents to the input query. Based on the relevance score, three different actions are considered before the generation step.
If the action Correct is triggered, the retrieved documents will be refined into more precise knowledge strips \(k_{in}\) (each strip can be as small as one or two sentences ). This refinement operation involves knowledge decomposition, filter by relevance score, and recomposition of strips with high scores.
If the action Incorrect is triggered, the retrieved documents will be discarded. Instead, external web searches are used to supply complementary knowledge sources for corrections. The knowledge source is denoted as \(k_{ex}\).
If the action Ambiguous is triggered, both internal knowledge \(k_{in}\) and external knowledges \(k_{ex}\) will be used. Finally, the refined/combined knowledge will be used in the generator to produce final output.
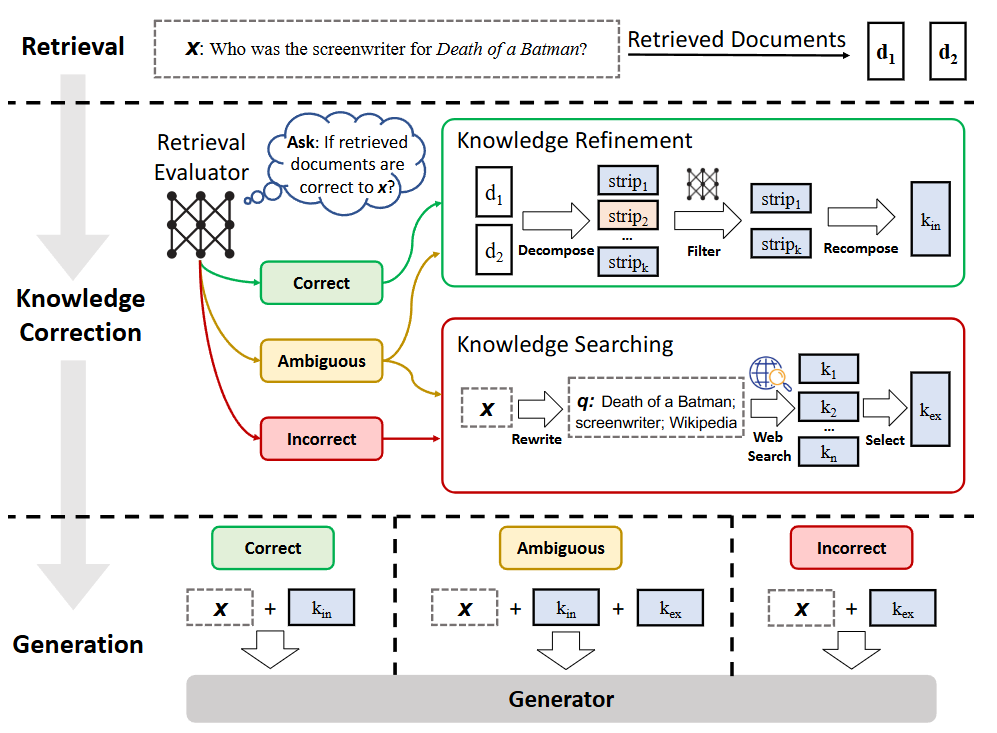
Fig. 27.1 Overview of the proposed CRAG at inference. A retrieval evaluator is constructed to evaluate the relevance of the retrieved documents to the input, and estimate a confidence degree based on which different knowledge retrieval actions of {Correct, Incorrect, Ambiguous} can be triggered. Image from [YGZL24].#
27.2. Self-Reflective RAG (SELF-RAG)#
27.2.1. Motivation#
The retrieval process in basic rag can introduce unnecessary or off-topic passages that mislead the generator to produce low-quality results. Moreover, the even with retrieved groundings, there is no guarantee that the generator’s output will be consistent with retrieved relevant passages.
27.2.2. Key Design#
The key design of SELF-RAG consists of the following:
Retrieval-on-demand. SELF-RAG first determines if augmenting the generator with retrieved passages would be helpful. It is implemented by asking the LLM to output a retrieval token that calls a retriever model on demand. For example,
The query How did US states get their names? requires retrieval.
The query Write an essay of your best summer vacation does not require retrieval.
Self-reflection during generation process. An LLM is trained in an end-to-end manner to learn to reflect on its own generation process given a task input by generating both task output and intermittent special tokens (i.e., reflection tokens) controling its retriever behavior and output quality. Specifically, reflection tokens provide citations for each segment with its self-assessment of whether the output is supported by the passage, leading to easier fact verification.
Reflection tokens are listed in the following table, which signal the need for retrieval or confirm the output’s relevance, support, or usefulness.
Type |
Input |
Output Class |
Definitions |
|---|---|---|---|
Retrieve |
\(x / x, y\) |
{yes, no, continue } |
Decides when to retrieve with \(\mathcal{R}\) |
IsREL |
\(x, d\) |
{relevant, irrelevant } |
\(d\) provides useful information to solve \(x\). |
IsSuP |
\(x, d, y\) |
{fully supported, partially supported, no support} |
All of the verification-worthy statement in \(y\) |
ISUSE |
\(x, y\) |
{5, 4,3,2,1} |
\(y\) is a useful response to \(x\). |
With reflection tokens controling the retriever and generator, we have the SELF-RAG algorithm summerized as follows.
Algorithm 27.1 (Self-RAG Inference)
Inputs: Generator LM \(\mathcal{M}\), Retriever \(\mathcal{R}\), Large-scale passage collections \(\left\{d_1, \ldots, d_N\right\}\); Input prompt \(x\) and preceding generation \(y_{<t}\).
Output: Next output segment \(y_t\).
\(\mathcal{M}\) predicts Retrieve given \(\left(x, y_{<t}\right)\)
If Retrieve == Yes then
Retrieve relevant text passages \(\mathbf{D}\) using \(\mathcal{R}\) given \(\left(x, y_{t-1}\right) \quad \triangleright\) Retrieve
\(\mathcal{M}\) predicts IsReL given \(x, d\) and \(y_t\) given \(x, d, y_{<t}\) for each \(d \in \mathbf{D} \quad \triangleright\) Generate
\(\mathcal{M}\) predicts IsSuP and IsUse given \(x, y_t, d\) for each \(d \in \mathbf{D} \quad \triangleright\) Critique
Rank \(y_t\) based on IISEL, IISUP, IsUse \(\triangleright\) Detailed in Section 3.3
else if Retrieve \(==\mathrm{N} \circ\) then
\(\mathcal{M}_{\text {gen }}\) predicts \(y_t\) given \(x \quad \triangleright\) Generate
\(\mathcal{M}_{\text {gen }}\) predicts ISUSE given \(x, y_t \quad \triangleright\) Critique
With each generated segment being assessed, the best segment is used as the final output.
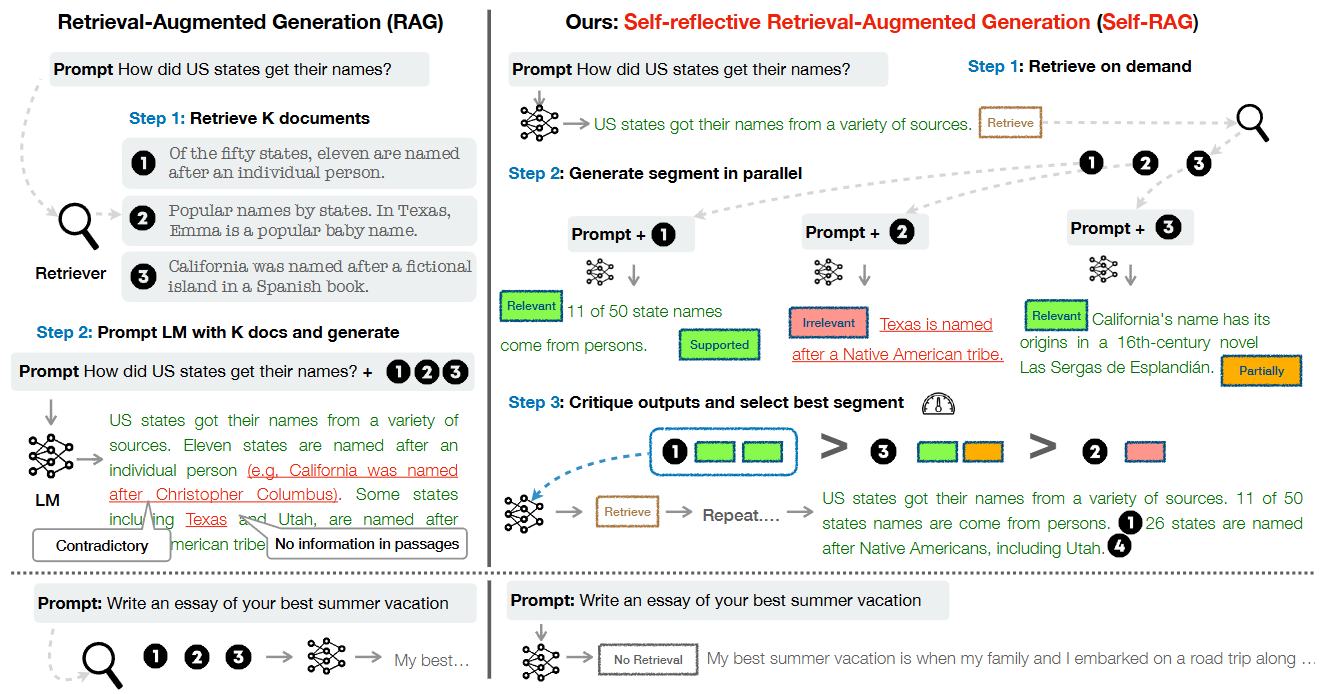
Fig. 27.2 Comparison of naive RAG vs self-RAG. Self-RAG learns to retrieve, critique, and generate text passages to enhance overall generation quality, factuality, and verifiability. Image from [AWW+23].#
Central to SELF-RAG is a LLM that can generate self-reflection tokens. Such a self-reflective LLM is trained end-to-end with next token prediction task on a diverse collection of text interleaved with reflection tokens and retrieved passages. The most straightforward way to create the annotated training data is to leverage a critic LM to annotated raw training data. For example, the retrieve token can be produced by prompting GPT-4 with a type-specific instruction Given an instruction, make a judgment on whether finding some external documents from the web helps to generate a better response.
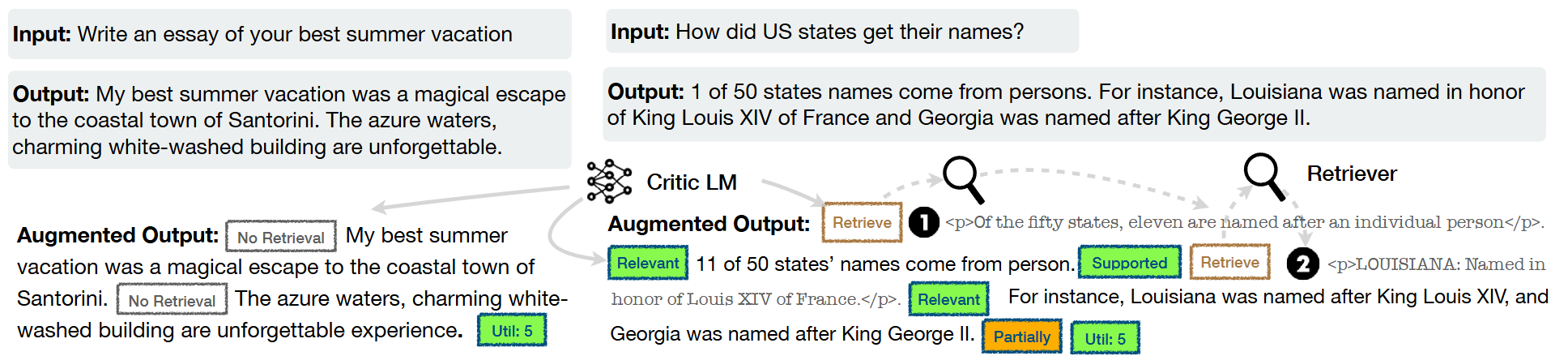
Fig. 27.3 SELF-RAG training examples. The left example does not require retrieval while the right one requires retrieval; thus, passages are inserted. Image from [AWW+23].#
27.3. Agentic RAG#
Based on the image, I’ll explain the concept of Agentic RAG (Retrieval-Augmented Generation):
Agentic RAG represents an evolution of traditional RAG systems by incorporating multiple specialized agents that work together to produce more accurate and reliable responses. The diagram shows multiple agents then work collaboratively within a structured framework:
The Planning Agent determines the strategy for answering the question
The Synthesis Agent processes and combines information
These agents interact with the search service to gather necessary information
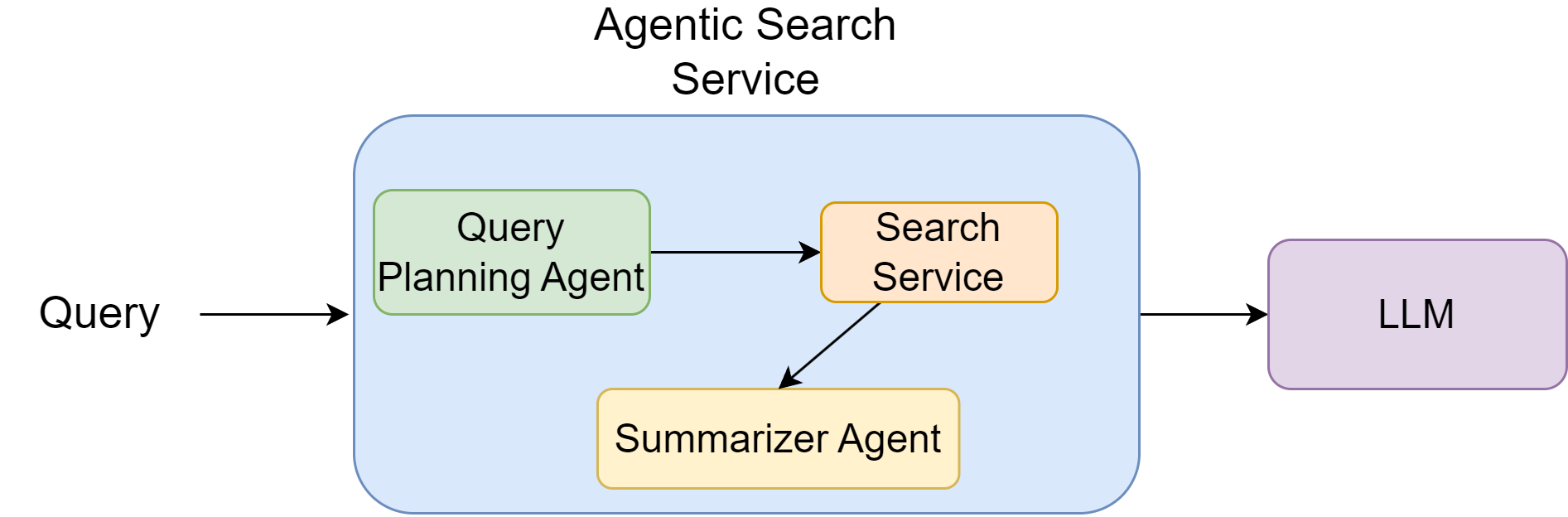
Fig. 27.4 Illustration of agentic RAG, in which multiple agents work collaboratively to provide grounding.#
What makes this “agentic” is the way it delegates different aspects of the task to specialized agents that each handle specific parts of the process - planning, searching, and synthesizing. This division of labor allows for more sophisticated reasoning and better accuracy compared to simple RAG systems that just retrieve and generate without this structured agency approach.
As shown in Fig. 27.5, the key innovation here appears to be the coordination between these different agents, allowing them to work together to break down complex queries into manageable steps and cross-validate information before producing a final response. This cooperative approach helps reduce errors and provides more reliable answers by combining multiple perspectives and verification steps.

Fig. 27.5 Agentic RAG example in breaking down a complex query into smaller manageable steps.#
While agentic RAG can improve the success on complex and reasoning-demanding queries, but it often comes at the cost of increased latency, higher resource usage, and potential reliability issues.
High latency: reasoning steps are lengthy, multiple calls to LLM are required; diffcult to manage and control the response time.
High cost: Multiple reasoning and search steps result in high GPU serving costs
Error prone reasoning: As there are multiple reasoning steps and each steps can cause error, the final reasoning outcome is error-prone. Reasoning steps might mistakenly reject correct answers.
27.4. GraphRAG#
Traditional vector RAG was created to help solve this problem, but we observe situations where baseline RAG performs very poorly. For example:
Vector RAG struggles to connect the dots. This happens when answering a question requires traversing disparate pieces of information through their shared attributes in order to provide new synthesized insights.
Vector RAG performs poorly when being asked to holistically understand summarized semantic concepts over large data collections or even singular large documents.
To tackle these challenges for baseline RAG, GraphRAG [[ETC+24]] was proposed by Microsoft to use knowledge graphs to aid question-and-answer when reasoning about complex information.
The GraphRAG process involves the following steps:
Extracting a knowledge graph out of raw text, usually using a LLM,
Building a community hierarchy for nodes in the knowledge graph,
Generating summaries or other meta-data for these communities,
Leveraging these structures when perform RAG-based tasks.
Compared with Vector RAG, which finds the top-k semantically related document chunks to use as context for synthesizing the answer, GraphRAG uses subGraphs related to entities in the task or question as context. More specifically, GraphRAG will have the following online querying process:
Search related entities of the quesion/task (the search could be keyword extraction based or embedding based)
Get subGraph of those entities (\(k\)-depth) from the knowledge graph
Build context based on the subGraph.
This allows GraphRAG to:
Capture Complex Relationships: Explicitly represent and reason over the connections between entities, enabling more accurate retrieval and deeper understanding of the knowledge base.
Enable Multi-hop Reasoning: Traverse the graph to connect information from different sources and answer complex questions that require multiple steps of reasoning.
Improve Explainability: Provide a clear path of how the system arrived at an answer by tracing the connections in the knowledge graph, increasing transparency and trust.
Example 27.1
GraphRAG can excel at queries requiring the reasoning and summarization over multiple sources. Example queries are:
What are the key events of the Russo-Ukrainian War.
Vector RAG might retrieve documents mentioning individual events but struggle to connect them chronologically and explain their overall impact on the conflict.
GraphRAG can effectively organize events as nodes in the graph, link them based on temporal and causal relationships, and generate a concise summary highlighting the war’s evolution.
Explain the role of Leonardo da Vinci in the Renaissance
Vector RAG might retrieve documents mentioning his various achievements (art, science, engineering) but fail to capture the interconnectedness of his contributions.
Graph RAG can summarize da Vinci’s diverse skills and accomplishments from interconnected nodes in the graph
27.4.1. Knowledge Extraction#
Example 27.2
Some text is provided below. Given the text, extract up to 2 knowledge triplets in the form of (subject, predicate, object). Avoid stopwords.
Example: Text: Alice is Bob’s mother. Triplets: (Alice, is mother of, Bob)
Text: Philz is a coffee shop founded in Berkeley in 1982. Triplets: (Philz, is, coffee shop) (Philz, founded in, Berkeley) (Philz, founded in, 1982)
Text: {TEXT} Triplets:
Input |
Output |
|---|---|
… I realized something that might seem obvious, but was a big surprise to me. There, right on the wall, was something you could make that would last. Paintings didn’t become obsolete. Some of the best ones were hundreds of years old. And moreover this was something you could make a living doing. Not as easily as you could by writing software, of course, but I thought if you were really industrious and lived really cheaply, it had to be possible to make enough to survive. And as an artist you could be truly independent. You wouldn’t have a boss, or even need to get research funding… |
(artist, could be, truly independent) (art, didn’t become, obsolete) |
…Interleaf had done something pretty bold. Inspired by Emacs, they’d added a scripting language, and even made the scripting language a dialect of Lisp. Now they wanted a Lisp hacker to write things in it. This was the closest thing I’ve had to a normal job, and I hereby apologize to my boss and coworkers, because I was a bad employee. Their Lisp was the thinnest icing on a giant C cake, and since I didn’t know C and didn’t want to learn it, I never understood most of the software. Plus I was terribly irresponsible. This was back when a programming job meant showing up every day during certain working hours. … |
(Interleaf, made, software for creating documents) (Interleaf, added, scripting language) |
27.4.2. Graph-based Retrieval#
Query Processing: The user’s query is analyzed to identify key entities and relationships.
Graph Traversal: The knowledge graph is traversed to find relevant nodes and paths that match the query. This may involve algorithms like breadth-first search (BFS), depth-first search (DFS), or shortest path algorithms .
Contextualization: The retrieved information is contextualized by considering the relationships and connections between entities in the graph. This process often involves identifying “communities,” which are clusters of closely connected nodes in the graph .
27.5. Bibliography#
Important resources:
Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi. Self-rag: learning to retrieve, generate, and critique through self-reflection. arXiv preprint arXiv:2310.11511, 2023.
Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, and Jonathan Larson. From local to global: a graph rag approach to query-focused summarization. arXiv preprint arXiv:2404.16130, 2024.
Shi-Qi Yan, Jia-Chen Gu, Yun Zhu, and Zhen-Hua Ling. Corrective retrieval augmented generation. arXiv preprint arXiv:2401.15884, 2024.